



How Databricks Saw the AI Future Coming
Databricks didn’t stumble into GenAI, it engineered the foundation for it years in advance - since 2013.
The company’s story begins with Apache Spark, the open-source engine created by Databricks’ founders to address one of the most pressing challenges in enterprise IT: processing massive, diverse datasets at scale. Spark’s speed and flexibility solved a critical bottleneck for organisations moving away from rigid, siloed data warehouses toward more agile, cloud-first infrastructure.
But Spark was only the first step. The real insight was that the hardest part of AI isn’t the model, it’s the data. Enterprises needed a platform that could:
- Handle structured, semi-structured, and unstructured data in a single architecture.
- Govern that data with enterprise-grade security and compliance.
- Make data pipelines reproducible, reliable, and scalable across business units.
That’s why Databricks pioneered the lakehouse architecture - a unified data platform combining the openness and scalability of data lakes with the performance and reliability of data warehouses. From the start, the goal was clear: eliminate the fragmentation that slowed enterprises down and make the jump from raw data to advanced analytics and AI as seamless as possible.
Fast forward to the current AI wave, and that architecture is proving its value. Features like Unity Catalog (for governance), MLflow (for experiment tracking and deployment) created by Matai Zaharia and co, and Vector Search (for GenAI retrieval workflows) are not bolted-on products. They are the natural extensions of a platform built around the principle that data is the core asset, and AI is only as powerful as the data platform beneath it.
This is why Databricks isn’t just keeping pace with the GenAI era, it’s setting the direction. Enterprises looking for a unified solution to move from ingestion to production AI find that Databricks already solved the upstream challenges, long before GenAI became the industry’s buzzword.
What "Leading" Means and Why It Matters Right Now
Databricks isn't "ahead" because of one shiny feature; it's leading because it's shipping AI faster and simplifying the enterprise stack whilst staying open. That's showing up in both the numbers and the product direction: Databricks just crossed a £4B+ annualised revenue run rate at >50% YoY growth, raised fresh capital at a £100B+ valuation, and says its AI products alone are at a £1B run rate, all whilst running positive free cash flow and serving 650+ £1M+ customers.
But what does "leading" actually mean in practice? It comes down to three critical differentiators that are reshaping how enterprises think about data infrastructure.
1. Outpacing Competitors in GenAI Feature Rollouts
a. The Competitive Landscape Reality

Databricks' AI products recently crossed a $1 billion revenue run-rate, while competitors struggle with different challenges:
Snowflake (~$75B market cap): Despite similar revenue scale (~$4B), Snowflake's growth has decelerated to ~29% compared to Databricks' 50%+. The company faces stiff competition from AWS, Microsoft Azure, and Google Cloud, which integrate data warehouses into their platforms while Snowflake pays fees to these same competitors for hosting.
Palantir (~$2.5B revenue): While showing accelerating growth with their AI platform (AIP), Palantir remains significantly smaller in scale and focuses primarily on government and specialized commercial applications rather than broad enterprise data infrastructure.
b. Databricks' AI-First Advantage

What sets Databricks apart is their AI-native approach rather than AI-as-an-afterthought:
- Agent Bricks: Production-ready AI agents optimized on enterprise data. Rather than generic chatbots that struggle with company-specific context, Agent Bricks can build agents that understand your business logic, imagine an AI agent that can analyse quarterly sales data, cross-reference inventory levels, and automatically generate procurement recommendations based on your company's historical patterns and current market conditions.
- Lakebase: A new operational database built specifically for AI agents. Traditional databases require human developers to design schemas and manage transactions, but Lakebase enables AI agents to create and manage their own operational layers. For instance, an AI agent processing customer support tickets can dynamically create new database tables to track emerging issue patterns, update customer records in real-time, and maintain transactional consistency without human intervention.
- Integrated MLflow, Vector Search, and Model Serving: AI capabilities that extend naturally from the data foundation. Instead of juggling separate platforms for experiment tracking, embedding search, and model deployment, a data scientist can train a recommendation model in MLflow, automatically index product embeddings with Vector Search, and deploy the model for real-time serving, all within the same governance framework that manages the underlying customer and product data.
CEO Ali Ghodsi notes that 80% of databases are now created by AI agents, up from 30% just one year ago, and Databricks is positioned at the center of this transformation.
2. Unified Data Infrastructure + Enterprise Grade Governance

Before Databricks vs. After Databricks
Before Databricks: Fragmented and Fragile
- Multiple silos: Data lakes for raw files, warehouses for reporting, and specialized systems for ML/AI.
- Complex integrations: ETL pipelines stitched together across products, often brittle and hard to maintain.
- Governance gaps: Security and compliance policies applied inconsistently across platforms.
- AI as an afterthought: Data scientists spent more time wrangling data than building models, while operational teams struggled to get models into production.
The result? High costs, slow innovation, tools spread across multiple platforms, and limited trust in data/AI governance.
After Databricks: Unified and Scalable
- One platform: A Lakehouse architecture where ingestion, storage, analytics, and AI all live together.
- End-to-end governance: Unity Catalog enforces consistent permissions, lineage, and compliance across the stack.
- Operational efficiency: Pipelines are reliable and reproducible; experiments are tracked, and deployment is standardized.
- AI by design: Features like MLflow, Vector Search, and Model Serving extend naturally from the data foundation—AI is not bolted on, it’s built in.
The outcome? Lower total cost of ownership, faster time-to-value, and enterprise-grade trust in AI.
In short, Databricks has set itself up to transform fragmented, fragile systems into a unified, governed, and AI-ready foundation. What was once a barrier to innovation becomes a platform for scale, enabling enterprises to move faster, reduce costs, and deploy AI with confidence.
3. Open, Extensible Ecosystem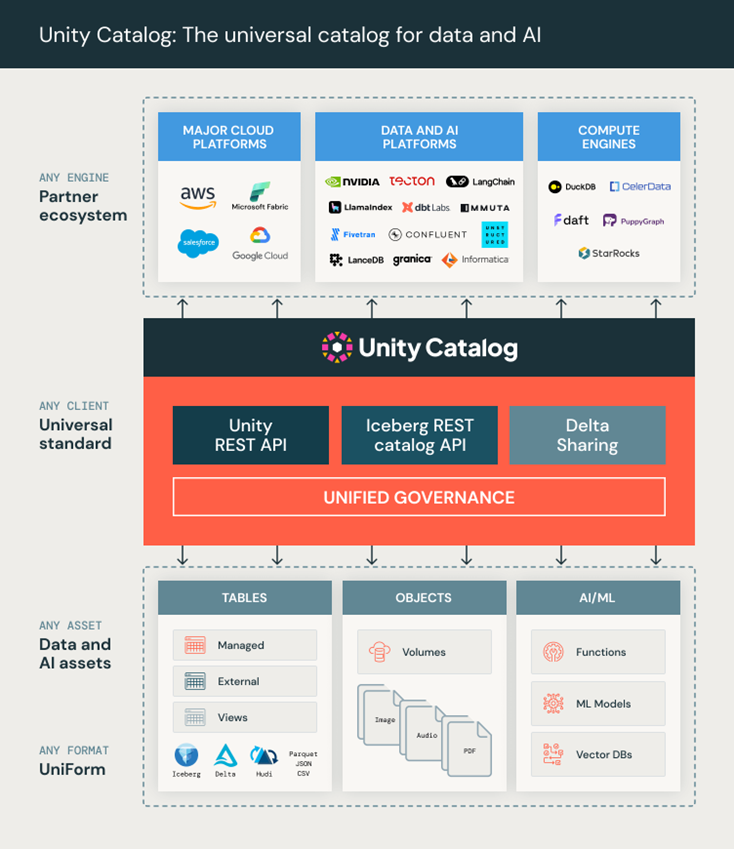
Databricks' leadership stems from their commitment to open-source foundations:
-
Open Data Formats & Data Governance
-
Beyond Spark, Delta Lake, and MLflow, Databricks’ integration with Apache Iceberg and support for formats like Parquet, JSON, and CSV ensure enterprises can adopt Databricks without replatforming existing investments.
-
Unity Catalog acts as a universal governance layer across Iceberg, Delta, and Hudi, ensuring enterprises are not forced into one proprietary storage choice.
-
-
Multi-Cloud Flexibility
-
Databricks runs on AWS, Azure, and Google Cloud, allowing enterprises to avoid hyperscaler lock-in.
-
This enables hybrid and multi-cloud data strategies — critical as enterprises balance cost, compliance, and sovereignty requirements.
-
-
Extensible APIs and Ecosystem
-
Unity Catalog’s APIs (REST, Iceberg REST, Delta Sharing) make governance extensible across any compute engine or AI platform.
-
Integration with LangChain, NVIDIA, dbt, Fivetran, Informatica, and others shows how Databricks is designed to be part of a broader AI ecosystem rather than a closed garden.
-
-
AI-Native Openness
-
With Vector Search, Model Serving, and Agent Bricks, Databricks builds AI capabilities on open data standards, not proprietary black boxes.
-
This ensures enterprises can extend existing models, integrate with external LLMs, and deploy AI in ways that fit their architecture rather than conforming to vendor constraints.
-
This open approach contrasts sharply with proprietary alternatives and ensures customers avoid vendor lock-in while benefiting from community innovation. Databricks has established partnerships with Microsoft, Google, SAP, Anthropic, and Palantir, becoming part of the enterprise AI supply chain itself rather than just another vendor.
Conclusion: Why This Moment Matters
The AI era is exposing a hard truth: AI is only as good as the data platform beneath it.
Databricks saw this more than a decade ago and built its foundation accordingly. Spark to Lakehouse to AI-native infrastructure. Competitors are now racing to adapt, but Databricks’ foresight means enterprises adopting its platform aren’t playing catch-up; they’re building on ground prepared long before the GenAI wave arrived.
Leadership in this context doesn’t mean having the flashiest features, it means reshaping the enterprise data stack so that AI can move from experiment to production at scale, securely and reliably.
That is the transformation Databricks has already enabled, and why it is not just keeping pace with GenAI, but setting the direction of enterprise AI itself.
Ready to Build on the Right Foundation?
As a Databricks Elite Partner, we help enterprises architect and deploy AI-ready data platforms-from lakehouse migrations to production AI at scale.