



Data quality is the kind of topic that gets the same reception as "Documentation" when discussing projects or data platform implementations. It's like convincing my 8-year-old to eat vegetables.... actually, that's harder.
It's an aspect of data management that sounds simple, and foundational. It's the key to doing anything useful with your data after all but it's also one of the least defined areas of most data platforms.
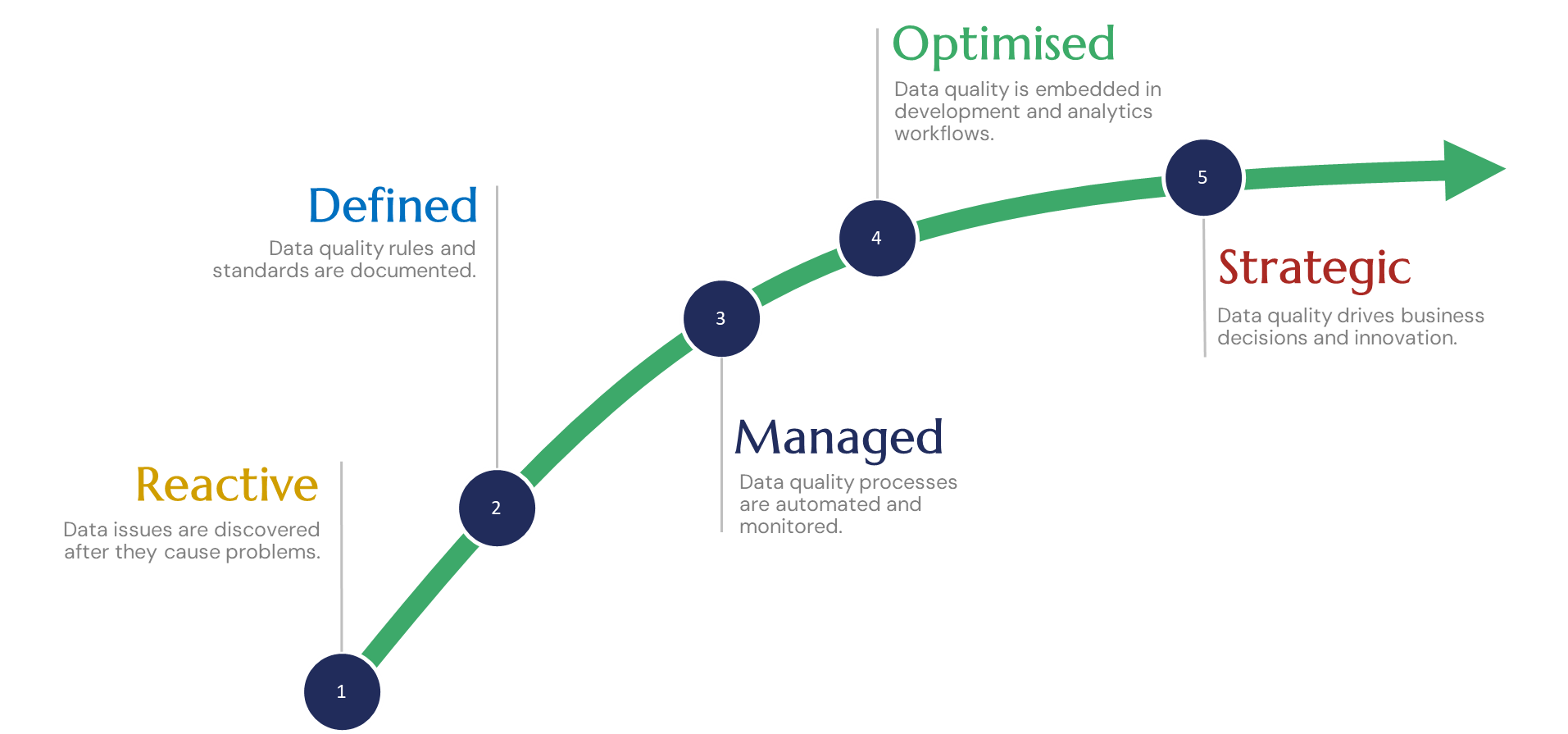
Most teams have some form of validation in place, but real data quality management is about more than tools and checks. It’s a mix of observability, process, and culture, working together to build trust in the data which is why you can't just buy a product and call it a day.
Where do you start?
The first step is visibility. If you can’t see what’s going on with your data, you can’t fix it.
Databricks gives you a few practical ways to do this. Declarative Pipelines (formerly Delta Live Tables) can automatically apply Expectations as part of your pipelines, showing where data is drifting from what you’d expect. Unity Catalog adds lineage so you can trace where data came from and how it changed along the way. Then add in Databricks Labs’ DQX Framework (an open-source Databricks Labs project) to extend that visibility by helping you define and manage quality rules directly within the platform.
Bring them together with Lakehouse Monitoring’s table-level metrics and anomaly-detection features, and you start to move from ad-hoc validations to consistent checks that give you a picture of how healthy your data really is.
But having this visibility isn’t enough on its own. Alerts, dashboards, and metrics only make a difference when there’s a culture that values acting on them. That means setting up clear responsibilities for who reviews data quality reports, building feedback loops to investigate issues, and making it normal to pause and ask why things are off instead of ignoring them to keep a pipeline green. The tools give you the signals, your processes and habits decide whether you listen.
Ownership
Now that you can see what's happening, what do you do about it, and who should be fixing it?
Strong data quality management comes from clear ownership and simple, repeatable processes. Define who owns a dataset, who fixes issues, and how those issues get raised. Even a small quality review or a shared backlog can make a big difference. Treat data quality problems the same way you treat software bugs - make them visible, prioritised, and measured.
Unity Catalog can help make ownership visible and enforceable. You can record who owns and manages each dataset through metadata, giving teams a single place to see who to contact when problems arise. Access controls and permissions reinforce accountability: if a team owns a table, they also control its changes and are responsible for keeping it healthy. Over time, building consistent metadata and ownership patterns in Unity Catalog turns data governance from something manual into part of everyday work.
Including data quality metrics in regular reporting also helps keep it part of the conversation, not just something that comes up when things break. It helps connect data reliability with business outcomes so people can see why it matters.
Proactive quality management
Most data quality work happens after something has already gone wrong. Do these steps sound familiar?

A more mature approach is to catch these issues before they even have a chance to surface.
Databricks makes this easier with anomaly detection and monitoring tools that learn from your data’s normal patterns and flag unusual changes automatically. You can use Lakehouse Monitoring to track trends in data volumes, schema changes, or value distributions, and set thresholds that trigger alerts when something looks off. This kind of proactive detection helps you focus your attention where it matters instead of reacting to every blip. It also helps maintain and even build trust in the data.
Beyond tooling, proactive quality management means baking checks and reviews into your delivery process:
- Validate new data sources before they go live
- Run automated tests as part of CI/CD pipelines
- Use historical insights to predict where data quality problems are most likely to appear.
It’s the same mindset as good engineering practices: don’t just fix the problem, design a system that stops it from happening again, like managing schema drift or quarantining erroneous records.
Build a culture that cares
No tool can replace a team that genuinely cares about accuracy. Good data quality depends on how people think about their work as much as the systems they use.
Encourage collaboration between data producers and consumers so that expectations are shared early. Reward people who find and fix problems before they reach production. Create an environment where questioning data isn’t seen as nitpicking but as part of doing good work.
Databricks gives you the building blocks for good data quality from a technology standpoint, but it only works when matched with the right habits and attitudes. Technology can highlight the issues, but people and process keep them from coming back. The best data platforms are those where everyone, not just engineers, feels responsible for keeping the data clean.
If you’re looking to strengthen your approach to data quality or build the right culture around it, our team at Advancing Analytics can help. We work with organisations to put the right processes, tools, and habits in place to make data quality part of everyday delivery. Get in touch if you’d like to talk about how to accelerate your data quality maturity.