



With the Advancing Analytics team having dispersed from San Francisco following an incredible week, here’s a quick overview of some of the Data Engineering announcements to come out of Data & AI Summit 2022.
Over the next week or so, the team will be publishing more blogs and videos to recap the event and offer opinions of the announcements, so keep an eye out for those.
Let us know what you’re most excited to get a closer look at!
Delta 2.0
One of the biggest cheers of the keynote was that Delta is being fully open sourced! Databricks continue to share their incredible work to help drive our industry forward. Delta already has wide adoption, but with the open sourced version now being levelled up to the same standard as the ‘proprietary’ one, this should help cement it as the default choice for lake-based storage.
There were some announcements of things to come with Delta too, such as a optimised deletes and updates by removing single rows instead of having to completely rewrite the file. It’ll be really interesting to see how this works, and just how much it boosts performance.

Delta Announcements
Delta Sharing and Cleanrooms
Delta Sharing is going Generally Available (GA), and has had more connectors added this year (such as PowerBI), and has more connectors coming soon (such as Terraform, Tableau, and Airflow).
On top of that, Cleanrooms was announced and has really caught my attention. It’s part of Delta Sharing and provides a way of tightly controlling access to your shared data sets. It looks to include things like external query approval, which means you’ll have total visibility of the data and aggregations people are trying (if approved) to view.
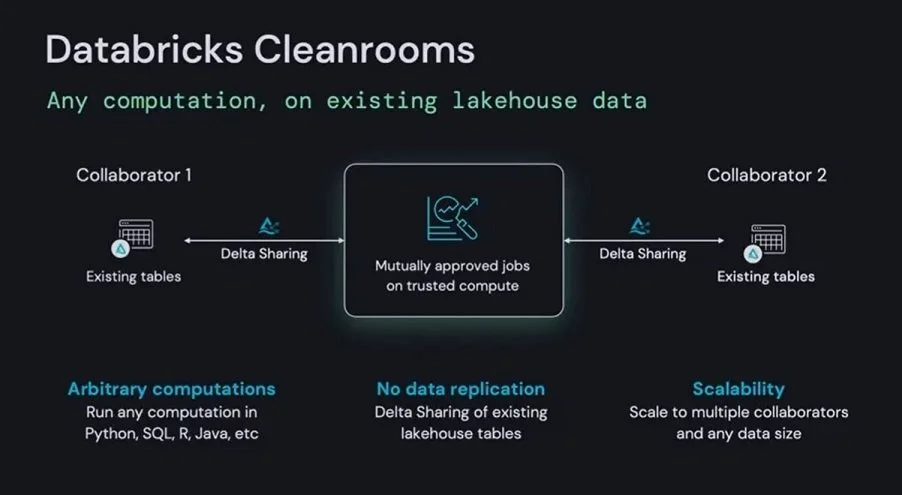
Databricks Cleanrooms Announcement
Databricks Marketplace
More than just a data asset marketplace for things like weather data, but also for ML models, solution accelerators like Hydr8, notebooks, and dashboards. There wasn’t much detail given around actually listing something in the marketplace or charging options, so it’ll be interesting to see how this all works.
Spark Connect
A new API for submitting Spark jobs. Will most likely open up better integration for IDE’s such as VSCode, but also means other lightweight applications will have a way of submitting Spark jobs. Perhaps developing notebooks from your watch is just around the corner?
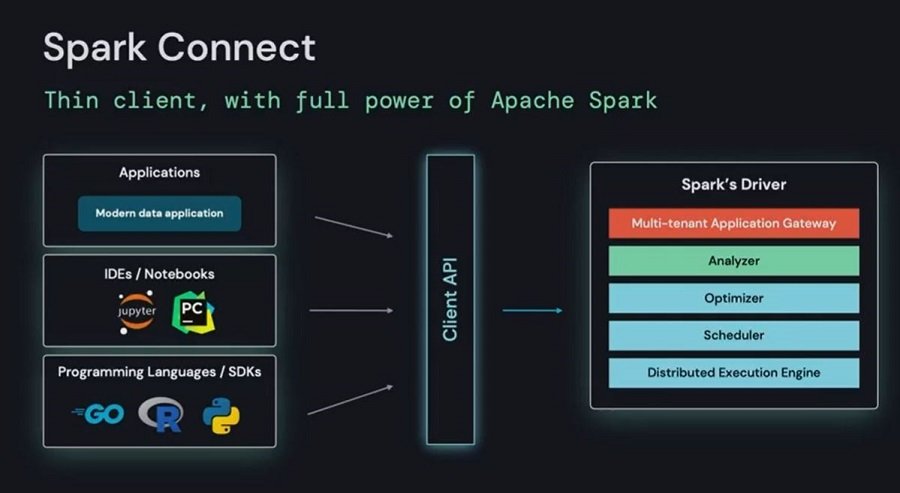
Spark Connect Announcement
Unity Catalog
This has been much anticipated. Matei Zaharia himself came out on stage to demo this one, with CEO Ali Ghodsi saying they’d put the ‘smartest man in the company’ on the project!
Matei’s demo did a great job of showing off some of the lineage capabilities, with both up & down stream lineage being available. Upstream being “Where this entity was sourced from” and downstream being “Where this entity is fed into”. Really handy for measuring impact of editting a particular notebook and building test plans for example.
Simon Whiteley’s already had a dig into this one and published a video, which you can see here; Advancing Analytics YouTube; Unity Catalog Intro.
Unity Catalog will be going GA in the coming weeks!
Databricks SQL Serverless
SQL Serverless has been in private preview for a little while, but it’s going public, although unfortunately only on AWS for now. We got some great sight of what it can do though, and a good look at their Serverless roadmap. Some of the key takeaways on SQL Serverless were:
-
There’s still a cluster, so it’s a little different to Synapse Serverless which is exciting.
-
Seeing start up times of around 10 seconds for initial query, but hope to have this as low as 2 seconds by the time it goes GA. 10 seconds may seem high, but remember right now it can take 5 minutes for a cluster to start up.
-
They are seeing customers achieve a 20-40% reduction in cost by eradicating wasted cluster uptime!
You can see the roadmap here on my Twitter; Serverless Roadmap. Serverless notebooks later this year by the looks of things!
Project Lightspeed (Streaming Improvements)
Databricks themselves have already published a ton of info on this, which you can find here;
The highlight for me is that they are talking about a 4x improvement in processing latency!

Project Lightspeed Announcement
Enzyme
A little bit cloak and dagger this one… Not entirely sure where it fits or what it really is, but it looks to be an ETL optimization project for Delta Live Tables (DLT) offering data ingestion/acquisition capabilities perhaps, a lot of talk about it’s ability to automatically choose the best method for incremental ingestion (or incrementalization as Michael Armbrust called it), such as append only, partition recompiling, or merging.
Sounds like a broad optimization to DLT, but if it does offer any acquisition capabilities then I’d love to see it as part of Workflows (below) too. Time will tell…
New SQL REST API
A new API targeted at Databricks SQL so you can launch queries at it from other services. Could enable things like embedding live visuals into web-apps backed by Databricks SQL.
Photon Improvements
Firstly, it’s going Generally Available (GA), but they’ve made a bunch of improvements with it too.
Some cool enhancements with Photon with it going GA, such as faster query plan generation. The example given during the key note given showed plan generation taking 1.8 seconds before the improvements and being optimised down to 0.7 seconds - a very nice 60% improvement! In both cases the query took 0.3 seconds to execute, so great to see such a reduction in the plan generation, where the majority of time is being spent.
There’s also something in the works called Metadata Pipelinging to further improve performance, and early tests have shown an additional 0.3 second improvement on the query above, which would mean a combined improvement of a whopping 83%!
Window Functions such as ROW_NUMBER and data sorting have both been optimised for improved performance. These will be in preview soon.
Databricks Workflows
A new method for orchestrating data platform operations within Databricks. It looks like a good start, but I think it has a little way to go before I’ll be picking it up over Data Factory.
For example it doesn’t look to have iterators yet (for each, while), the dependencies look a little basic as there’s no on-success/failure yet, but I believe all of this and more is on the roadmap. It does have parameters, but these weren’t included in the demo.
The default logging and monitoring looked great - super visual with some high level stats like late running pipelines.
If Enzyme (above) does turn out to be an acquisition engine, it would be lovely if it were integrated here…