



When DJ Patil said that Data Science was the sexiest job of the 21st century, many companies rushed to spin up data science capabilities. A lot of these companies did so without much consideration to the future! Many were motivated by the fear of missing out or were concerned their competitors would do the same and take the advantage.
As a result many data science teams were created without much consideration for the return-on-investment. As a result many of the now teams struggle to provide value and need to justify their existence.
Those who do and do it well are thriving. Those who do not are at risk. Why is it that some are thriving while other flounder? There is a simple answer. Those who can deploy models are more likely to succeed.
There are steps you can take to simplify the route in to production. One of those is by hiring a Machine Learning Engineer. Here are seven signs you might need a Machine Learning Engineer:
1. Your team is developing a lot of models, but they are not in production.
You and your team may have a lot of fantastic ideas, but seldom do those ideas make it in to production. Models live and die on a developers machine. This is a problem. How can you prove to the business that Data Science is a good idea if they can not see the value. Models should be developed with the deployment method in mind.
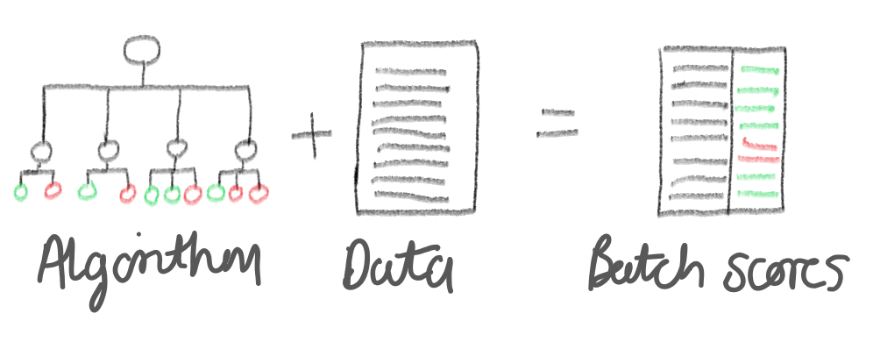
This could be a batch model, scored using R, Python, Spark or another. A batch file scored and saved somewhere for analysis. This might be consumed in to a data warehouse, or it might go into a LOB system such as a CRM to drive marketing.
You might be creating an interactive model which will need to be scored in real-time. An interactive model typically sits behind a REST API to ease integration in to an application or process. Or you might be creating a model which will be an interactive-batch model. An interactive-batch model is one which is trained in batch but exposed as an interactive model. As far as the application calling your model is concerned it looks and behaves like an interactive model, however it is a batch file loaded in to a fast database with a serverless API on-top.
Each has a different method of deployment, and developing a model should factor this in before development begins. A Machine Learning Engineer can help guide a team on how best to do this.
2. You do not retrain models

There is a fallacy amongst many Machine Learning teams that once a model is trained it is perfect. If you build a model and it achieves an accuracy which you're happy with and it is generalised enough to support predictions going forward, you may choose to put that into production. The second that model has been trained, it begins to decay. The rate of decay depends on the data used to train the model. If you train a Churn model looking at the last 6 months pf customer behaviour, that model may be accurate for a time, but that model will begin to slip. When should you retrain?
You might decide to retrain after a week, a month, a year? It depends on what is right for the business and the model. You could decide to retrain your models on a wall clock. On the 1st of every month retrain the model. This might be ok, however you may be under-training or over-training that model. Either of which is going to have an impact on the accuracy of your model and its ability to generalise to the business objective.
3. You do not capture model logistics
Wall clock retraining might work some modes, however a better option would be to capture in the incoming requests and dynamically calculate the right time to retrain.

You have a model which calculates the micro-segmentation of your customers - It is doing a classification of a handful of key features. You train the model using your current customer list. 25,000 customers. The model works well. You organically grow and gather 1000 more customers. Their behaviours mirror those of a normal customer. Do you need to retrain, possibly not. The business continues to grow and you purchase a smaller business. 20,000 new customers are added to your portfolio. Their behaviours are vastly different to the original 26,000. You need to retrain, but not immediately.
A good way of detecting when you need to retrain is by capturing the incoming requests. Each time a model is scored, you capture the parameters which were requested and store them in a database. You can then look at the original training set and calculate what we be a sensible range to retrain at. What is sensible will depend a lot on the type of model you're making and the type of prediction. If you're scoring using an interactive model, typically there quest will b in JSON, therefore a great store for that is a document store such as Azure CosmosDB.
4. Model latency is a problem/Your models are not elastic.
Models need to be elastic. You may create a model and deploy it. The business integrates that in to an AB Testing element of the website for a small cohort of customers. The model does well! The business has seen an uplift of 25% on customers who are given recommendations based on this new model. The latency for the model is ok, it is scoring in approximately 90ms. The business expose it to more customers, the latency has started to be effected. The model is scoring now in 130ms.
The business sees a similar level of uplift and rolls the model out to all of their customers. The model is being scored 100 times a second. Latency shoots through the roof at 1100ms and the website begins to slow down and customers move to a different platform. The model could not scale. Models going through an AB Test is a common scenario and one that should be accounted for. Our models need to be elastic, they need to be able to grow with the demand, and shrink then demand reduces. Kubernetes is a container orchestration solution and has many ways to make the process of scaling configurable and as easy as issuing a command.
5. You cannot support multiple models, orchestrating to achieve a single business objective.
Multi-model orchestration is an advanced model management technique. You run a business where people play games on your website. You want to keep them playing games, so you create a churn model. Customer churn is an interesting problem as you will find there are different groups of customers in your population. New customers will churn in different ways to those who have used your platform for many years. You may want to create two models and have both scored in parallel. Then decide which model retunes the best option for that circumstance.
This can also extend to a challenger/incumbent model scenario. You have a model, a Random Forest looking at making a decision whether or not to give someone a loan. This model is in production and is a key decision making tool. The business has changed a lot since it was trained and you need to retrain the model. You create v2 of the model. You test it and the accuracy is good. You wish to replace the old model with a new model. The problem you are faced with is that the business does not want to take the risk of switching the model. They want to phase the old model out. Lots of vendors will try to sell you a Smart Load Balancer as an option. This will not work. Both models should be scored so you can see the comparison.
6. You can only deploy models in one language.

You may have made a decision as a business to make a language your default language for all machine learning projects. There are some good reasons for doing this. It ensures that everyone on the team is learning the same language, you can better handle model dependencies and your training requirements are reduced. The listed benefits are great, however what you're doing is hindering the growth of the team and reducing the flexibility of the team.
Let's say you have decided that R is your production language for Machine Learning. Some on your team comes to you with a fantastic new paper on Generative Adversarial Networks (GAN) which they found on Reddit (r/MachineLearning). They think it will apply to a problem you have, problem is that the examples are all in Pytorch. You only use R and unfortunately cannot explore this option as it is not available in R.
Not only have you limited the tools a developer can use, you have prevented on a process which would offer business value. As a data science manager or Head of Data Science, you cannot enforce a single language for production. Sometimes R is best for a problem, other times Python is good. If someone reads a paper on “Zebra” or the latest and greatest ML framework then use it, but just make sure you're using it in a way that it is protected from other applications. Read more about using Docker for this on Advancing Analytics.
7. Operations have to re-write your models in a "production" language
This is an extension of the problem above. You may have decided that you want to allow your team to build in any language they deem best, however, Operations are not happy. You build a model in R and as Operations to deploy it for you. There is a problem, the operational language is Java. Operations will need to rewrite your model in Java before they deploy it. You agree, this process takes six months. In that time your model has decayed and will need to be retrained. Operations are not data scientists and have not built the model how you did. As a result the accuracy has decreased and the model is no longer production ready. You need an architecture for deploying a model in a way that will keep operations happy.
Operations are concerned about production code and that what is being deployed will not have an impact on production systems or impact the customer's journey. They want to deploy code they are sure will not impact production systems. How can we do that? We need to leverage tools outside of the production systems. Docker and Kubernetes are great for this. Operations are concerns about latency, well Kubernetes will load balance our models and ensure that as demand grows the latency of scoring out models does not become an issue.

Thanks for reading. If this post struck home with you and your Machine Learning development processes then you probably need a Machine Learning Engineer.
on't worry you're not alone, this is a problem in our industry. If you look on indeed.com you will typically find a 1:31 ratio of Machine Learning Engineer to Data Scientist roles. This is staggering and goes to show that there is a problem. Most customers I talk to tell a similar story of their development process. Model are never making it in to production. If you want to improve and automate the route to production then you need a Machine Learning Engineer. The role of a Machine Learning engineer is to know how to deploy and manage a model deployment. They should know how to leverage a REST API, create an image in Docker, deploy it to Kubernetes in the cloud and monitor it to track for decay.
Advancing Analytics is on-hand to help. We offer a variety of services all designed to support your data science journey. We are passion about Machine Learning. We build models and more importantly we automate their deployment. I have a philosophy in life, not to do the same thing more than once. As a result we have pioneered DataOps processes to accelerate models in to production. Take a look at our services and get in touch if there is some way we can help.
While you're there, check out some of our technical sessions and our Podcast, Data Science in Production.

