



Data has value – I think we’ve finally got to the point where most people agree on this. The problem we face is how long it takes to unlock that value, and it’s a frustration that most businesses I speak to are having.
Let’s think about why this is.
After the horror that was the “data silo” days, with clumps of data living in Access databases, Excel spreadsheets and isolated data stores, we’ve had a pretty good run with the classic Kimball data warehouse. Lots of organisations have them, they’re fairly well centralized and controlled – people are terrified of returning to the dark days of data silos and rightly so.
However, a data warehouse is a large, sanitary data store. To be successful it requires discipline and rigor. You need data validation & cleansing routines, test coverage, methodical UAT phases and more. What does this mean? To add new data to a warehouse, you need that most precious of commodities – time. In this scenario, time means two things – firstly, missed opportunities and secondly, development expense.

Expense is a tricky one – expense means investment, investment means having an idea about return on that investment. Calculating ROI up-front is a killer of fast innovation; you can spend so long trying to figure out ROI that you miss your initial opportunity. So how do you reduce the need for up-front ROI? Simply put, you make the “I” as small as possible. You reduce the amount of investment needed, aka, the development effort required to start experimenting with that data.
That’s an important differentiator for me – we’re not focusing on reducing the amount of effort to get that data into a clean, sanitised warehouse. We’re reducing the effort we expend for the early-sight analysis, the experimentation, the proof-of-concept. If we uncover some real value, then sure, we can productionise that into our warehouse, except now we know the value it’s delivering. We’ve not had to invest up-front, before finding out that value.
That, for me, is the “Data Lake” argument in a nutshell. There are objections we hear all the time:
“Why do I need a lake if I have a data warehouse already?
“My source data is relational, what’s the point of pulling that into a lake?”
“We’re not data scientists, we don’t need a lake”
And it’s the simple fact that a data lake, because of its inherent schema-on-read, unstructured nature, gives you the speed and agility to respond quickly to new opportunities. It’s not a replacement for a warehouse and it’s not even a new concept. But for companies looking to capitalise on their data and really innovate, it’s a necessity.
Let’s see what happens to our value realisation when we perform our analysis up front at the lake layer:

By circumventing costly warehousing, we can start working with our data much, much faster. That’s what’s driving the “Modern Data Warehouse” thinking, that’s why you’ll see many architectures having both a lake layer and a warehouse layer. They’re not exclusive, they’re complementary ideas that come together to form a whole solution.
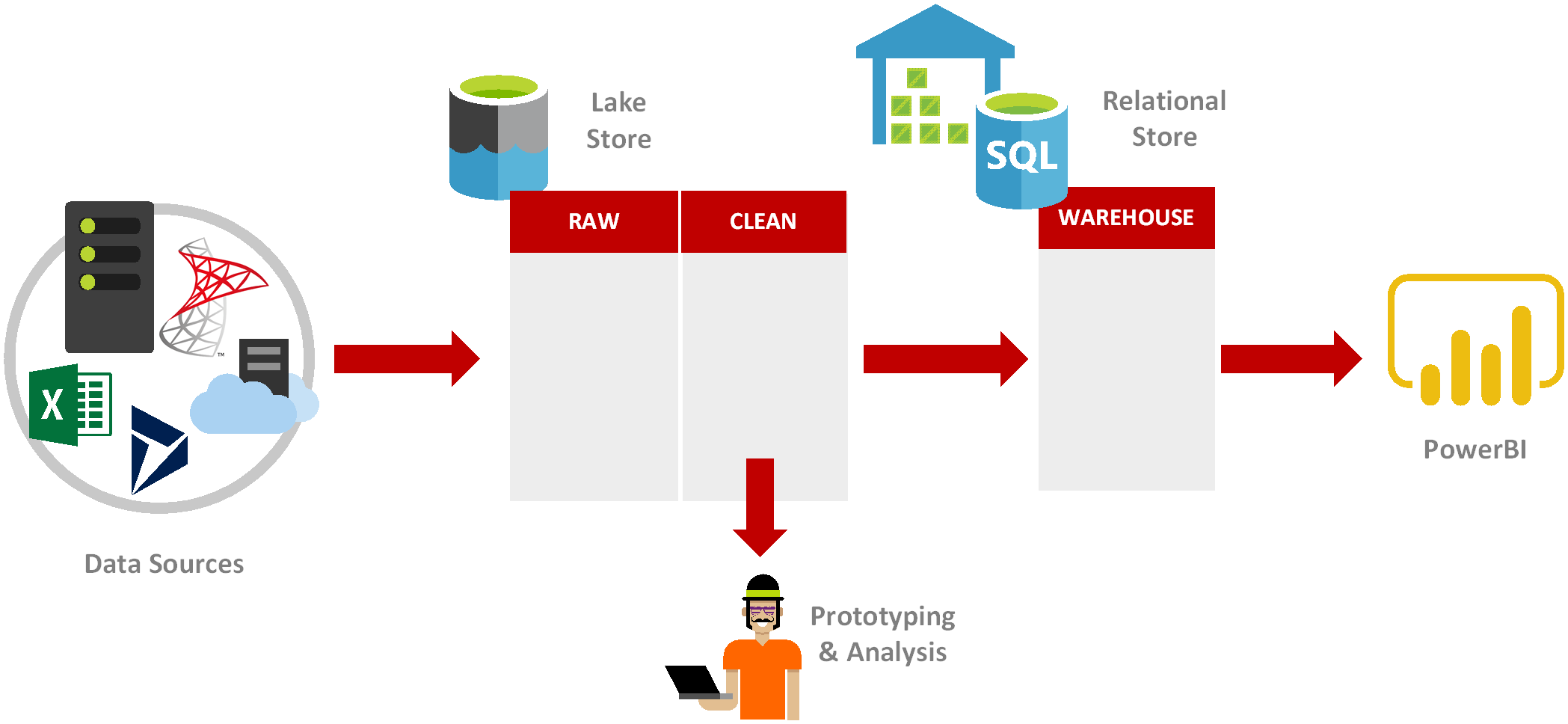
We take our classical idea of a data warehouse driven from source data. We add a new lake layer, this layer can be used for upfront analysis, ad-hoc experimentation and much more and gives some desperately needed agility to the traditional warehousing paradigm.
This is also an incredibly important touchpoint if you’re creating a platform for both traditional warehousing and data science. You can load data and begin experimentation very quickly, whilst still providing a step towards eventual warehousing goals – we’ve aligned two very different but also complementary analytics functions.
Sure, there’s much more to it than that, but I hope you’ll agree that there is real business value in getting to your data quicker and not investing in costly warehousing before value has been proven.
If you’d like to know more about augmenting your warehouses with lakes, or our approaches to managing lakes and agile data delivery, please get in touch at simon@advancinganalytics.co.uk.
Till next time.
