



Businesses are currently in a data Gold Rush. With the vast array of Data Sources and types of Data available currently; any Business that can harness this Data into insights is more likely to succeed.
Because of the sheer amount of Data and variety available, a Business needs a platform that can be flexible enough to handle this: The Data Lakehouse. Having data and a platform is not enough though, you need to organise your Data if you want to avoid your Lake becoming a swamp!
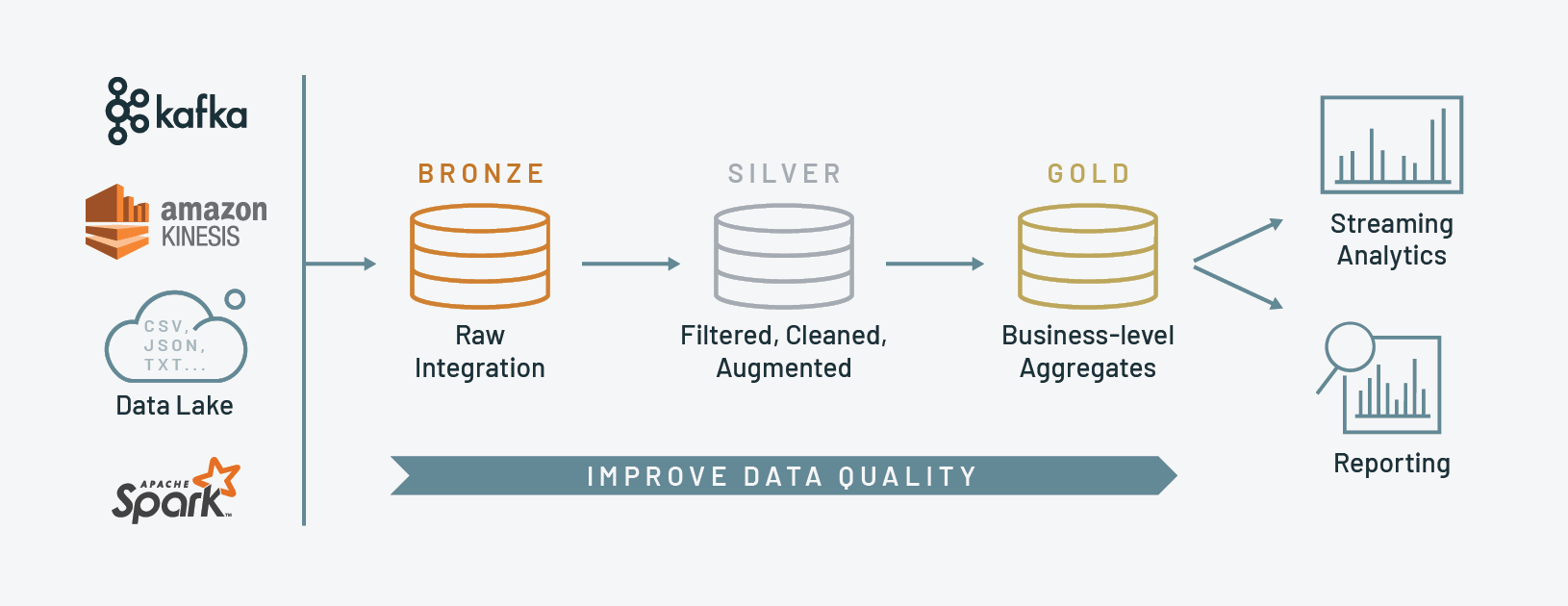
Medallion Architecture is a system for logically organising data within a Data Lakehouse. A standard medallion architecture consists of 3 main layers, in order: Bronze, Silver and Gold. The increasing quality of precious metal in the names is no accident and represents an increasing level of structure and validation when moving through the layers. This architecture is sometimes also known as multi-hop architecture.
Databricks Medallion Architecture
But what is a Data Lakehouse?
Data Lakehouse is gaining popularity in the data world as an idea that aims to bring together the best parts of Data Lakes and Data Warehouses. Data lakes are flexible; they can handle unstructured data and storage and compute are decoupled. Data Warehouses have better structure and governance. They also have ACID Transactions (Atomic, Consistent, Independent, Durable). By combining Data Lakes and Data Warehouses the idea is to have access to the best parts of both but fewer of the limitations. The Data Lakehouse is made possible by the Delta Lake storage framework.
Delta Lake
Delta Lake is a storage format based on Apache Parquet. Delta Lake is an open-source project that anyone can contribute to. Delta includes Parquet files, a checkpoint file and a transaction log in the form of JSON files which provides ACID transactions and versioning.
ACID Transactions
ACID is an acronym for 4 key properties intended to guarantee data validity.
Atomicity guarantees transactions are applied as a “unit” which either completes or the transaction fails and the data is left unchanged.
Consistency ensures that a transaction cannot bring data from a state that is consistent to a state which in inconsistent so for example data of a different type to a column cannot be loaded into it.
Isolation effectively ensures that concurrent transactions are in effect executed sequentially if they affect the same table.
Durability ensures that transactions are not complete until they are recorded in memory. Once a transaction is complete it is complete even in the case of a system failure.
Bronze Layer
In the Bronze layer, the data is first ingested into the system at this point the data will be completely unvalidated. Usually in the bronze layer data will be loaded incrementally and will grow over time. Data ingested into the bronze layer may be a combination of batch and streaming.
Although the data is kept in a mostly raw state; additional fields may be added which may be helpful later (in searching for duplicates etc). These could be fields such as a source file name and load date.
Data in the bronze layer should be stored in a columnar format such as Parquet or Delta. Columar storage is great because it stores data in columns rather than rows. This can provide more options for compression and allow for more efficient querying of a subset of data.
Silver Layer
Upon ingestion into the silver layer, data is filtered, cleaned and augmented. This could mean the data is deduplicated, missing data is handled, incorrect data is removed or corrupted data is fixed.
Data validation rules are applied; this could be things like ensuring there are no nulls in the data, that data is unique, that data is the correct type and format and performing logical checks such as if it’s a country field checking that it’s a country that exists and is spelt correctly. You could also perform checks such as whether all orders have an order date or whether an order date is always before a dispatch date.
In the silver layer data from different source systems is generally not joined together yet but data may be enriched with reference data, an example of this would be using a lookup table to replace Country or State codes with a more readable version
Data in the silver layer should ideally be stored in Delta format to start to take advantage of the features of Delta. This means that schema will be enforced so trying to load data which doesn’t match the schema will fail. However, using Delta new columns can automatically be merged into the schema (Schema evolution) or loaded into a rescued data column for manual inspection and remediation.
Gold Layer
Going into the gold layer the data is transformed for specific use cases and Business level aggregation is applied.
At this level business rules are applied. Suppose a company wants to know its preferred customers. The company has decided that a preferred customer must have spent £10,000 in the most recent calendar year. A table can be created that sums customer orders by year to answer this question.
At this level data from different source files or systems may also be joined together. In the previous example customer data may need to be joined with sales data to create a customer sales table.
Data in the gold layer should be stored in Delta format to make use of features like the ability to restore a previous version perhaps in the case of a processing error.
Other Layers
There may be a use case for also having additional layers other than Bronze, Silver and Gold. An example of this which is often used is Landing. There may be a need for data from source systems to be dropped in a location before being ingested to Bronze. For example, sometimes you may want to drop files in Landing in CSV, JSON or XML format before ingesting into Bronze as Parquet or Delta.
In some implementations there may also be a separate presentation layer or even multiple presentation layers for different audiences. The presentation layer would generally contain different views of the data in the gold layer, in the case of having multiple presentation layers each one might contain a subset of data that is important to a certain audience.
Other names
Different implementations will often use different names for the layers and there are no rules about what names must be used. It is common to see different names such as
Raw > Validated > Enriched
Raw > Base > Curated
Raw > Stage > Curated

Advancing Analytics’ layers
There are several reasons to use a different terminology for layer names. Some people believe it is better to have a more descriptive name of what the layers are. Some people believe using Bronze, Silver and Gold doesn’t make sense when using additional layers. Finally, Gold can be confused with Golden record of Master Data Management so a different naming convention can avoid confusion.
How is this different to what I have done before?
If you have worked with Data Warehouses and are familiar with a BI Architecture like Src > Stg > Ods > Edw Medallion Architecture should feel familiar. It is not a completely new idea, it’s just a reinvention of a tried and tested way of managing data validation and transformation.
In the current Big Data landscape Data Lakehouse and Medallion Architecture is a winning combination which provides a great way to organise and validate your data; using a Medallion Architecture can help you turn raw data into Gold.