



I am irked.
As a father of two high school aged children, this is not uncommon, but for once they are not the source of my ire.
On this occasion, it’s the following widely distributed image, taken from the Databricks website:
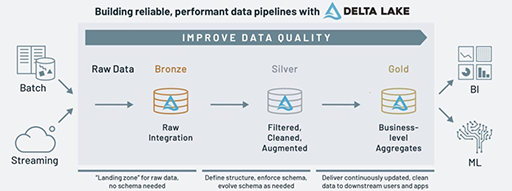
What’s the matter?
What is causing me this annoyance? Could it be the slightly clumsy but somehow now de facto naming convention used for the Lakehouse layers? No, I’ll leave that rant to boss man Si Whiteley.
My issue is with the description of the Gold layer, specifically the phrase “Business-level Aggregates”.
What’s in a word?
What does the word “aggregate” mean to you? I recently asked that question on my Twitter feed, and aside from the odd joke about “small stones used for building” here are some of the responses I got:
· It means you took the data from a lower grain to a higher grain. In other words, when you look at an aggregate, it means you're not looking at the lowest level of detail of which the data is available.
· sum, count, avg, min, max etc
· those functions that break SQL because I forget the group by... Or more sensible answer - the functions to summarise my data - SUM COUNT being the obvious 2
Most of my Twitter followers are fellow data professionals, and the most common answers from that particular audience all followed a theme, involving using some kind of mathematical function to summarize data.
Framed as a fairly open ended question, I don’t think any of those answers are incorrect. And if we take dictionary definitions, that fits ok too. One definition is as follows:
“a sum or assemblage of many separate units; sum total ”
But “aggregate” is one of those wonderful marvels of the English language known as a homonym. It’s a word that can actually have several different meanings.
From the same Collins Dictionary entry as the above definition, we have an alternative:
“formed of separate units collected into a whole; collective; ”
Ambiguity
The issue with the Gold layer definition provided by Databricks in their medallion architecture diagram is that their use of the word aggregates is ambiguous.
The default word association of many data professionals is the former definition, leading many people to believe that the “Gold” layer of the Lakehouse means pre-aggregated data. But despite the plethora of plaid shirts in our midst, this is not the 90’s and we’re not supposed to be trying to mimic the early incarnations of OLAP cubes.
I like to think of this version of “aggregates” to be akin to a news aggregator website. The purpose of those types of website is to curate the best sources of news and bring them all together in one place, making it easier for people to consume information about the current affairs of the day. The intention is not to summarize that news in a set of TLDR-esque snippets. You get the articles in full from many different places, but served up in an easier to navigate manner.

Bing!
The Microsoft Bing homepage is a good example of a news aggregator website.
Sound familiar? A well designed data warehouse, or gold/curated layer in a Data Lakehouse does the same thing! Taking data from disparate sources, consolidating it in to a defined set of objects that transcend those sources and serving them up in a manner that end users can consume in order to make sense of their business and drive decisions.
Aggregation Confusion
Connotations of aggregation from a “to summarize” perspective are dangerous and in fact a bit of an anti-pattern. If we revisit the sage advice of Kimball (okay, maybe it is still the 90’s!) then he advocates for understanding your granularity and modelling your data at the atomic level. This gives you far more flexibility further down the line when trying to add new data sources and/or events to your data models. And yes, I’m saying that Kimball is still very much relevant in a Lakehouse world.
In fact, when you actually read the accompanying literature with the now infamous Databricks diagram, there is zero mention of the word aggregate. The emphasis is much more on curation and modelling. Which make me wish they would just change the damn diagram and remove the ambiguity.
There are cases when summarising the data makes sense. Maybe you need to roll up to a common grain to conform a concept across separate sources or as a means to help boost performance in some scenarios, so the SQL engine doesn’t have to scan so much data. But these should still be built on top of data already modelled at the atomic grain, not as replacement for them.
...just to confuse you some more
At this point I’m going to introduce even more confusion to my point, as we’ve recently released our own solution accelerator called Aggreg8, which allows rapid development of robust semantic layers in Power BI. That actually ticks both of the aggregate boxes as it both consolidates objects across domains in to a single model, whilst also facilitating roll up and summarisation across those objects… But I can assure you, that’s a different thing.
Rant Over!
There, I feel much better for getting all of that of my chest.
If you’re struggling to get your head round the best way to structure and build a Lakehouse and want some help navigating your way through the confusion and ambiguity surrounding Lakehouse layer design, don’t hesitate to get in touch at hello@advancinganalytics.co.uk.
We’ve been working in the Lakehouse space for quite some time now and we promise that we won’t accidentally aggregate your data when in fact what you wanted was for us to aggregate your data.