



It’s an emotive question, and probably one that will be as divisive as the Kimball Vs Inmon debates of the past, but it’s one that I’m being asked more and more. Regardless of the answer, I’m thrilled that the question is being asked at all! For a technical area that is evolving at an incredibly rapid pace, the world of analytics is still steeped in tradition – far too many times I ask a question and get the response “because that’s how we’ve always done it”. If people are challenging their assumptions, that’s fantastic either way.
Why Kimball?
For those not familiar with the eponymous Ralph and his work, the Kimball approach to warehousing is behind the dimensional star schemas that we know and love. You build a central fact table that strictly only has the items you want to measure and separate anything else out into dimension tables. But why is this good? With traditional relational databases, data from each table is stored in row pages on disk. To read a column value from a particular row, you have to pull out the whole row as the database has no way of seeing where that attribute lies within that row. If you’re aggregating a particular column across billions of rows from your fact, you’re going to have to read everything else in those billions of rows. This drives the design to make the fact rows as thin as possible to ensure you don’t have to read a huge amount of unnecessary data, just to answer your query. This makes a lot of sense for relational databases using a row-based storage mechanism. The downside of this is that you’re having to perform table joins in your query – but that’s what relational databases are optimised to do, so it’s not too big a hardship.
For many years, that’s given us the following pattern. We bring data in, we clean & validate it, put it into a Kimball Multi-dimensional Warehouse then push out some smaller data marts for specific business areas.
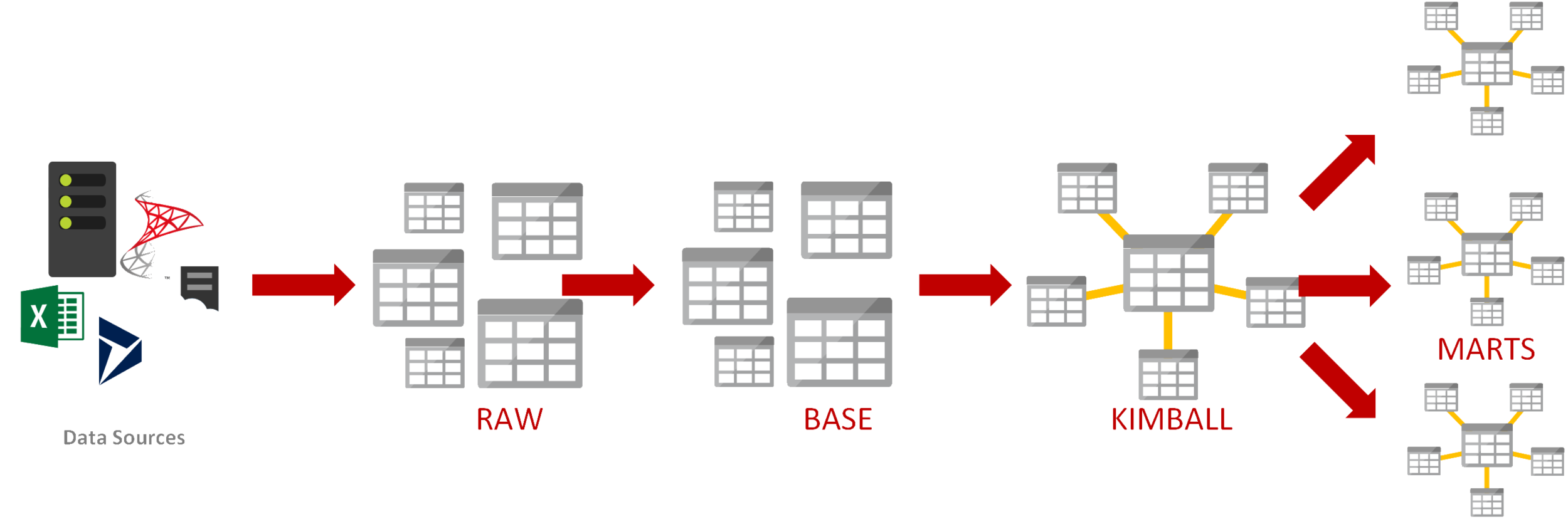
What’s changed?
So why are we questioning this eminently sensible approach? Two reasons – columnar storage and parallelism.
In our earlier example, we keep our facts nice and thin as we don’t want to read whole rows that contain data we’re not interested in. With columnar storage (columnstore in SQL Server, parquet as flat files and many more) the data isn’t stored row by row but instead as compressed column segments. Each column is stored separately – this means that you can read some columns and not others. So having a huge, wide table with all of your data stored in one place adds no overhead to the performance of your query. Instead, you’re eliminating joins, which only serves to make things faster.
Which brings us to parallelism – you’d thing that anything working in parallel is just going to make things faster, right? Well yes… but with additional considerations. If I was previously performing a join on a single box, I just churn through both tables, getting as much into memory as possible and performing lots of repeated lookups if I can’t. But parallel systems can’t quite work that way – let’s take Databricks (and therefore Apache Spark) as an example.
I have a two-node cluster and I want to join two tables together. My executors will each bring a subset of data into memory and perform their queries. In an optimal world, the slice of Table A held on worker 1 only has joins to records in Table B that also happen to be on worker 1. The subset of records held in A.2 have foreign keys pointing only to records in B.2. Essentially, we have a clean split and have grouped the data together.
Current training course:
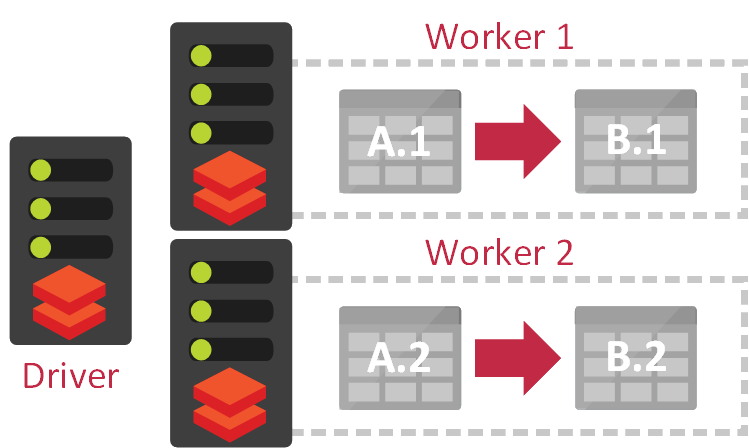
Cross-Worker Queries
With distributed queries comes great power… and great potential for an expensive amount of data movement & shuffling…
But how do I decide how to split that data to get that optimal join? What if the first table on executor 1 needs data from the second table on executor 2? They can’t constantly look up against each other, so I end up shuffling data around, churning partitions and ruining lots of the performance increase my parallelism had bought me. To be honest, this is fairly trivial to solve when we’re talking about just two tables, but you can imagine when you’re doing a traditional warehousing task – performing a query on a fact table against some fifteen or twenty dimensions, suddenly you hit a wall of potential pain. Especially if several of those dimensions are fairly hefty, fact-grain style dimensions. In these cases, pulling those dimensions onto the fact itself, would solve performance quite nicely.
So… do we get rid of Kimball then?
Actually…. No. We’re just not doing it for the same reasons.
The wide, denormalised table is a pure performance argument. It’ll eliminate joins and speed up queries, but it makes other tasks a lot harder. I’m talking about data management, all of the other things that come along with a Kimball warehouse. Think about making a Type 1 slowly changing dimension, ie: “when I update this attribute, I want to update all historic occurrences of this attribute”. In our wide denormalised table, that means running huge update queries that could potentially touch every record in our data model. What was previously a single record update is now a major operation.
If I show my data model to a user, what was once a set of logically grouped attributes becomes one giant list of every potential attribute in the model that they have to look through. If I want to add a new attribute to one of my ‘dimensions’, that’s now another huge operation.
If I want to plug an element of master data management into my warehouse, creating a conformed dimension that can be used by a whole range of different data models… you guessed it, that’s now a whole additional headache if I try and do each data model as a single wide table.
Let’s say I have a product called “Bikes”, and that falls under the category of “Children’s Toys”. After some political manoeuvring, it’s now agreed that “Bikes” are “Fitness & Sport” products, not toys. In the Kimball world, this is a nice easy update to a couple of records. In our giant, de-normalised table, this is a HUGE update to the hundreds and thousands of order lines for a “Bike” product.
What does this mean?
OK, so we’re keeping Kimball when we’re doing data warehousing, even if it lives in a platform that uses parallelism and columnar storage, not because of performance but for the various data management processes a Kimball model enables.
But we shouldn’t discount the performance improvement we could provide to users who are querying these models by giving them a denormalised table. In the world of the modern data warehouse, this just means taking our “data mart” layer and considering replacing that with wide reporting tables. Remember, in a lake these aren’t simply transient layers with only the end-destination in mind – each of the steps described below are persisted filestores that can be queried for their own use-cases.
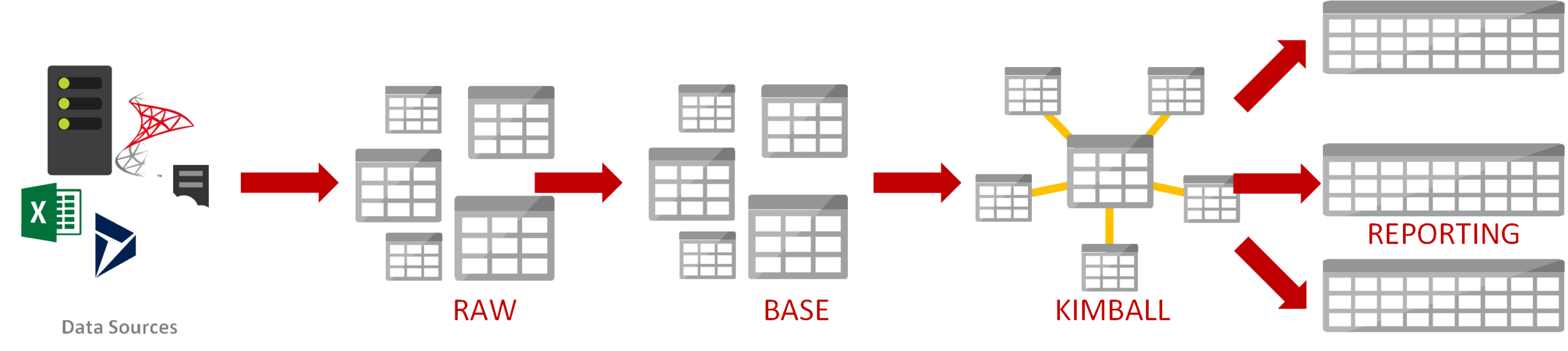
Or maybe there’s a mix – we create some data marts where the end recipient would appreciate a structured dataset and wide reporting where the recipient is more interested in pure analytical performance. That’s what the modern data warehouse gives us – the flexibility to choose, to have different solutions for different use cases, without the hefty up-front investment.
One thing to note is, of course, Kimball isn’t the only way to skin the warehousing cat and there are many proponents of Data Vault & Inmon in this world. However, both approaches encounter similar issues to the ones we’ve discussed – at some point you’ll need to perform a lot of joins to get your analytical queries answered and offloading this as a separate reporting layer is still going to provide benefits.
If you’d like to know more about augmenting your warehouses with lakes, or our approaches to managing lakes and agile data delivery, get in touch at simon@advancinganalytics.co.uk. You can also find us at various conferences, sharing our modern warehousing experience, such as the PASS Summit later in 2019 – find out more here!
Till next time.
