



MLOps (Machine Learning Operations) is the set of processes for the production ML lifecycle, basically a way to efficiently and reliably deploy and maintain ML models in production.
Below is a typical Advancing Analytics MLOps lifecycle:
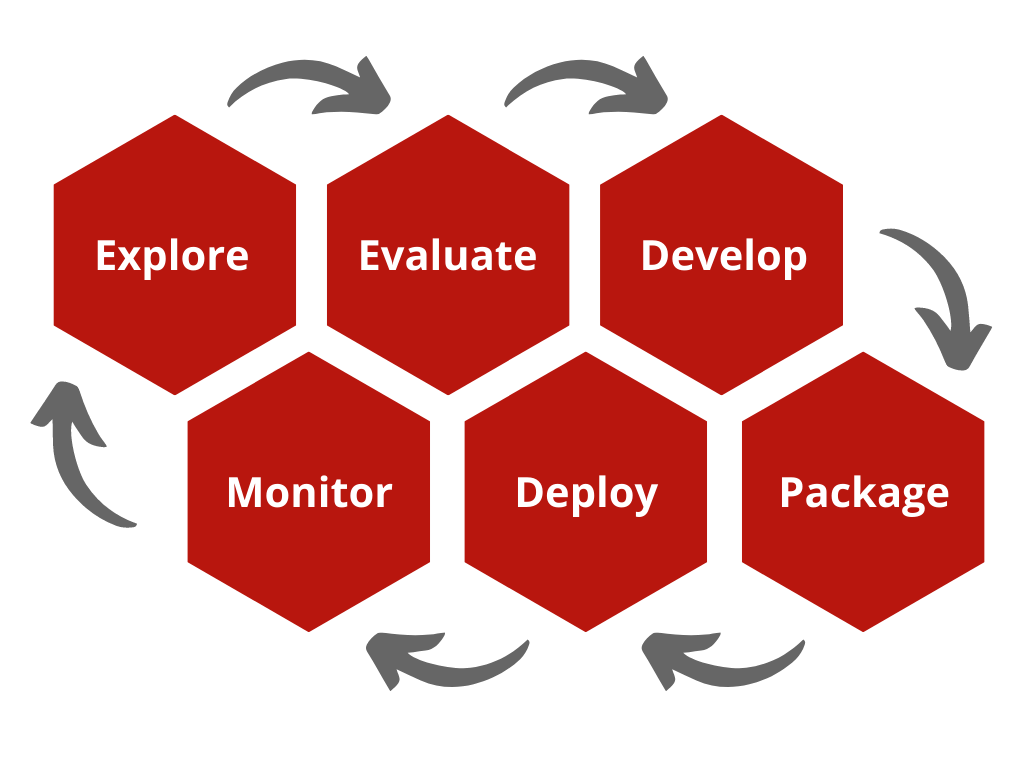.png)
It consists on an:
· ‘Explore Phase’, a phase for Data Scientists to experiment with models and typically where POC’s end
· an ‘Evaluate Phase’, where the model will be effectively evaluated for accuracy, business value and risk
· a ‘Develop Phase’, where Data Scientists and ML Engineers are likely to collaborate to create an inference pipeline that considers software development practices like unit testing and robustness
· a ‘Package Phase’, a phase dedicated to ensuring the model, training pipeline, inference pipeline and data is properly versioned and prepared to be deployed
· a ‘Deploy Phase’, where a fully robust inference pipeline is deployed
· and finally, a ‘Monitor Phase’, a phase for continuous monitoring of an ML model both for performance and drift.
Eventually you may need to retrain or replace your model, so the lifecycle will begin again. MLOps plays an integral part of each of these phases, so let’s explore this deeper.
Explore Phase

A ML project will typically begin in an ‘Explore Phase’ where a data scientist or team of data scientists will explore the data they currently have and experiment with models, algorithms, parameters and features. MLOps at this stage is responsible for supplying Data Scientists with environment they need to achieve this. One way this can be done is by leveraging Feature Store.
A feature store is a tool for storing commonly used features. As data scientists create new features then can log these into feature stores such as Feast and Databricks Feature Store, they can reuse these features across teams and projects. This will benefit teams in multiple ways by reducing compute times for both training and inference, provide consistency in common features and reducing effort for create complex logic.
Another way is by utilising tools for experiment tracking such as MLFlow. Data Scientists will be able to track experiments, models and parameters to allow them to benchmark performance against other models or return to previous models.
Finally, an important part of making this exploratory phase truly collaborative is to ensure Data Scientists are working in a centralised area such as Databricks ML Workspaces. That allows them to share resources such as model tracking and feature stores mentioned above.
Evaluate Phase

After a model has survived the ‘Explore Phase’ it needs to be effectively evaluated. This doesn’t just include accuracy.
One aspect that needs to be evaluated is if the model predictions offer enough business value. This is also the right time to consider how the model should be served. Is the model a book recommender which is intended to supply recommendations to sent as weekly emails? Then you will probably consider a batch model. Is the model going to recommend books at a click of a button on a website? Then a real-time inference deployment will be needed. It’s important to establish how the model will be used at the stage as it will drive future decisions in future phases.
Another way MLOps is essential at this stage is by evaluating the model’s fairness and interpretability especially in highly regulated sectors. You will want to assess the model’s fairness by leveraging libraries such as Fairlearn to test if it is over or underestimated demographics, reinforcing stereotypes or failing to apply the same quality of service to different end users.
Interpretability is understanding how and why a model has provided an insight, which is especially important when explaining outputs to non-technical stakeholders and for compliancy purposes in heavily regulated sectors such as insurance and medicine. Libraries such as SHAP and InterpretML can be utilised at this stage to achieve this. It’s not uncommon at this stage for a model to need further tweaking so an experiment may alternate several times between the ‘Explore’ and ‘Evaluate’ phases before moving forward.
Develop Phase

So, your model has been thoroughly evaluated and you wish to deploy it for the business or your consumers to use. First you must create a fully robust inference pipeline. Typically, a data scientist won’t have a software engineering background so will understandably overlook production-ready necessities such as data and model versioning, auditing and unit testing. MLOps is essential for bridging this gap between Data Scientists and ML/DevOps Engineers.
Data and model versioning can be accomplished using tools mentioned in earlier phases such as a feature store or MLFlow. This step is important eventually your model may encounter categories it not seen before, or a retrained model may cause an unexpected problem so you will need to debug or revert your model to a previous problem as soon as possible so your model isn’t offline for too long.
Creating a robust inference pipeline is also a vital stage of MLOps for similar reasons, just like any piece of software a model in production a user may input unexpected data. Your deployed model shouldn’t be brought down by a new category, mistake or a malicious attempt so you will need to create tests and build in robustness as this stage.
Package Phase

The very last step before deployment is to ensure your inference pipeline is being ran in a similar environment to when it was trained. This means knowing the version of all the libraries you use for your inference pipeline and deploying it with the exact same versions. This will evade any versioning errors that may affect your model. This may also include ensuring you will be able to access external tools you may be using such as MLFlow or H2O once your model has been deployed.
Deploy Phase

Finally, you can deploy your model. This step is the broadest because different models have completely different deployment requirements. One way, MLOps can ensure consistency in your approach is by building deployment patterns for models based on their requirements. You may want a pattern for a model to be ran in batch on Databricks or a load-balancing real-time model ran in Kubeflow depending on your businesses needs. There are many things you will need to consider including size of the model, minimum latency requirements, A/B testing, autoscaling and security access. If you want to know more about what deployment options there are in Azure, you can check out the following blog.
Monitor Phase

The work doesn’t stop once the model has been deployed. All models will eventually degrade over time and with that so will the accuracy of the predictions and trust of your end users. To avoid this, you will want to monitor your model for data drift. You can leverage algorithms such as Jenson-Shannon Divergence or track summary statistics over time to identify when your model has begun to drift. You will want to be alerted when the drift is significant and you may even want to trigger an auto retraining pipeline on the new data. You can learn about the different types of data drift and how to mitigate them in a previous blog.
Additionally, performance monitoring is recommended. If you are on Azure you can do this through App Insights or Log Analytics. Metrics such as requests, average latency and failed request count will tell you how the model is being used and whether adjustments need to be made. The MLOps cycle will eventually begin again when the model degrades or no longer fits requirements. With a good MLOps platforms, this will cause limited disruptions.
Why Do You Need MLOps?
I hope you can see now that MLOps is integral to taking a data science model all the way from creation to production and practicing MLOps will allow your team to create, deploy and monitor models in a reusable, reliable way. There is a huge number of platforms, tools and frameworks to help you achieve this and the ones mentioned in this are just a fraction.
