



In this blog series I explore a variety of options available for DevOps for Databricks. This blog will focus on working with the Databricks REST API & Python. Why you ask? Well, a large percentage of Databricks/Spark users are Python coders. In fact, in 2021 it was reported that 45% of Databricks users use Python as their language of choice. This is a stark contrast to 2013, in which 92 % of users were Scala coders:
Spark usage among Databricks Customers in 2013 vs 2021
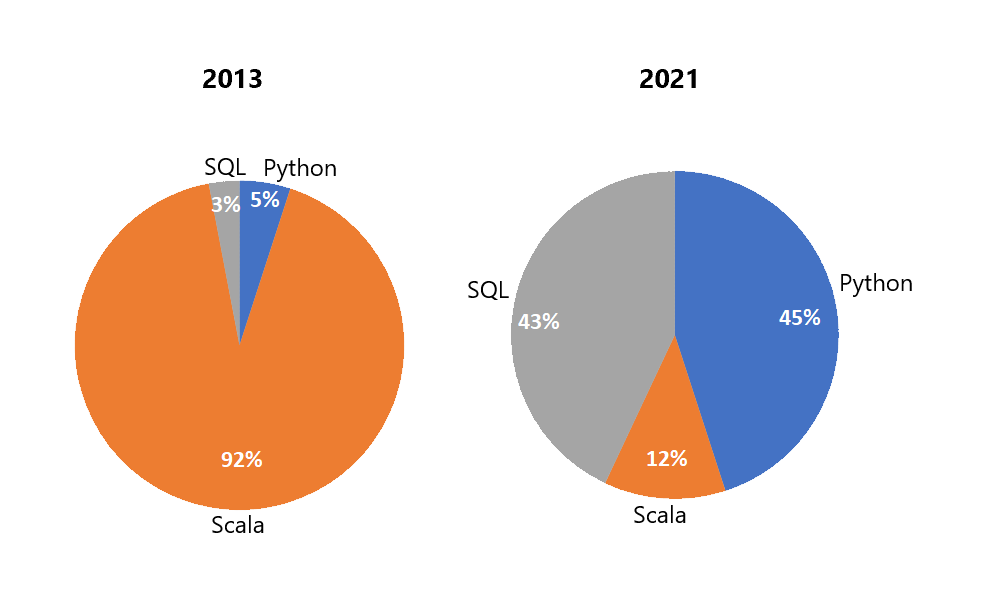
So, this blog is for those 45% Python Developers wanting to use Python to fulfil their DevOps needs.
Getting Started
So, we’ve identified we can use the Databricks REST API to perform our DevOps actions, the first thing we want to do is to categorize the actions we want to perform and subsequent API endpoints we want to work with. Assuming we already have a Databricks workspace created, we want to:
· Create a Cluster
· Start/Restart a Cluster
· Upload Notebooks
Authentication
We will be working with Databricks in Azure for this blog, so we need to authenticate with Azure accordingly. Within Azure, authentication can be carried out using a Databricks PAT (Personal Access Token), or Azure Active Directory Tokens (User specific or Service Principal). For this demonstration we will be using a Service Principal that has been granted access to the Databricks workspace, documentation on how to create a Service Principal in your Azure environment can be found here: https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal.
Once you have your Service Principal, make sure you have to hand your:
· Service Principal ID
· Service Principal Secret Key
· Your Azure Tenant Directory ID
We can now start writing some Python to authenticate. We will be authenticating against Microsoft/Azure, thus we use the following URLs https://login.microsoftonline.com/ and https://management.core.windows.net/, returning tokens for later use in our Python. First thing we need to do is to set up 3 properties:
1) Token Request Body: REST request body, this is where we specify our Service Principal ID and secret
2) Token Base URL: The Microsoft URL used to Authenticate (and return a token)
3) Token Request Headers: As standard with this sort of request this specifies the content type
import requests
import os
TOKEN_REQ_BODY = {
'grant_type': 'client_credentials',
'client_id': ['Service Principal ID'],
'client_secret': ['Service Principal Secret key']}
TOKEN_BASE_URL = 'https://login.microsoftonline.com/' + ['Azure Tenant Directory ID'] + '/oauth2/token'
TOKEN_REQ_HEADERS = {'Content-Type': 'application/x-www-form-urlencoded'}
We need to get 2 tokens, a “Management Token” and a “Databrick Bearer Token”. As per the Microsoft documentation here https://docs.microsoft.com/en-us/azure/databricks/dev-tools/api/latest/aad/service-prin-aad-token. So, we create 2 Python methods respectively that will get our tokens for us:
def dbrks_management_token():
TOKEN_REQ_BODY['resource'] = 'https://management.core.windows.net/'
response = requests.get(TOKEN_BASE_URL, headers=TOKEN_REQ_HEADERS, data=TOKEN_REQ_BODY)
if response.status_code == 200:
print(response.status_code)
return response.json()['access_token']
else:
raise Exception(response.text)
return response.json()['access_token']
def dbrks_bearer_token():
TOKEN_REQ_BODY['resource'] = '2ff814a6-3304-4ab8-85cb-cd0e6f879c1d'
response = requests.get(TOKEN_BASE_URL, headers=TOKEN_REQ_HEADERS, data=TOKEN_REQ_BODY)
if response.status_code == 200:
print(response.status_code)
else:
raise Exception(response.text)
return response.json()['access_token']
When we run these methods, we want to make sure we set the outputs to variables we can use later in our Python code:
DBRKS_BEARER_TOKEN = dbrks_bearer_token() DBRKS_MANAGEMENT_TOKEN = dbrks_management_token()
To utilize our tokens in all our API calls the following request header “DBRKS_REQ_HEADER” must be provided:
DBRKS_REQ_HEADERS = {
'Authorization': 'Bearer ' + DBRKS_BEARER_TOKEN
'X-Databricks-Azure-Workspace-Resource-Id':
'/subscriptions/[subscriptionid]' +
'/resourceGroups/devopsfordatabricks/providers/Microsoft.Databricks/workspaces/[workspace name]',
'X-Databricks-Azure-SP-Management-Token': DBRKS_MANAGEMENT_TOKEN }
Python Packages
Our Python scripts will be using the following Python packages:
1) requests: Used universally as the package of choice for HTTP requests in Python (our REST API requests)
2) os: Operating System package enabling us to access files/folders we wish to upload to Databricks
import requests import os from os.path import isfile, join from os import listdir
Now we have our tokens and required packages we can start to create our python methods
Create a Cluster
The following Python code illustrates how to create a cluster, to run you will need:
1) Your Azure Databricks Workspace URL
2) DBRKS_REQ_HEADER (detailed above)
def create_cluster():
DBRKS_START_ENDPOINT = 'api/2.0/clusters/create'
postjson = """{
"cluster_name": "devops-cluster",
"spark_version": "7.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"autotermination_minutes": 10,
"autoscale" : {
"min_workers": 1,
"max_workers": 3
}
}"""
response = requests.post("(['DBX-WORKSPACE-URL']/"
+ DBRKS_START_ENDPOINT,
headers=DBRKS_REQ_HEADERS,
json=json.loads(postjson))
if response.status_code != 200:
raise Exception(response.text)
os.environ["DBRKS_CLUSTER_ID"] = response.json()["cluster_id"]
print(response.content)
The “postjson” variable (json) is for you to change accordingly with the cluster configuration you require. Here we have some example configuration to get you started
Start/Restart a Cluster
Now we have our cluster we want to be able to start it, and further down the DevOps path we will need to be able to restart it. The below Python methods perform these tasks accordingly, requiring you to provide the Databricks Workspace URL and cluster ID.
To run you will need
1) Your Azure Databricks Workspace URL
2) Databricks Cluster ID
3) DBRKS_REQ_HEADER (detailed above)
DBRKS_CLUSTER_ID = {'cluster_id': ['CLUSTER-ID']}
def start_dbrks_cluster():
DBRKS_START_ENDPOINT = 'api/2.0/clusters/start'
response = requests.post(['DBX-WORKSPACE-URL']
+ DBRKS_START_ENDPOINT,
headers=DBRKS_REQ_HEADERS,
json=DBRKS_CLUSTER_ID)
if response.status_code != 200:
raise Exception(json.loads(response.content))
def restart_dbrks_cluster():
DBRKS_RESTART_ENDPOINT = 'api/2.0/clusters/restart'
response = requests.post(
['DBX-WORKSPACE-URL'] + DBRKS_RESTART_ENDPOINT,
headers=DBRKS_REQ_HEADERS,
json=DBRKS_CLUSTER_ID)
if response.status_code != 200:
raise Exception(json.loads(response.content))
Monitor Cluster Status
So, we have a cluster, but how do we monitor it and/or check its state before performing actions?
It’s important to note here that whilst working with the REST API every action/request we make is “Fire and forget”, what do I mean by this? Well, we may be telling Databricks to create a cluster via the REST API, in which is returns a status of 200 (OK), but this is the command, not the action itself. Once we have received our 200 response it does NOT mean the cluster is created, simply that Databricks has successfully acknowledged our request. Databricks will then take our command and begin creating the cluster. Consequently, the action itself could fail and we would never know, walking away with our 200 status thinking everything is ok. How do we address this? Well, in this tutorial we are going to write methods that polls the cluster status.
To run you will need
1) Azure Databricks Workspace URL
2) Databricks Cluster ID
3) DBRKS_REQ_HEADER (detailed above)
def get_dbrks_cluster_info():
DBRKS_INFO_ENDPOINT = 'api/2.0/clusters/get'
response = requests.get(['DBX-WORKSPACE-URL'] + DBRKS_INFO_ENDPOINT, headers=DBRKS_REQ_HEADERS, params=DBRKS_CLUSTER_ID)
if response.status_code == 200:
return json.loads(response.content)
else:
raise Exception(json.loads(response.content))
def manage_dbrks_cluster_state():
await_cluster = True
started_terminated_cluster = False
cluster_restarted = False
start_time = time.time()
loop_time = 1200 # 20 Minutes
while await_cluster:
current_time = time.time()
elapsed_time = current_time - start_time
if elapsed_time > loop_time:
raise Exception('Error: Loop took over {} seconds to run.'.format(loop_time))
if get_dbrks_cluster_info()['state'] == 'TERMINATED':
print('Starting Terminated Cluster')
started_terminated_cluster = True
start_dbrks_cluster()
time.sleep(60)
elif get_dbrks_cluster_info()['state'] == 'RESTARTING':
print('Cluster is Restarting')
time.sleep(60)
elif get_dbrks_cluster_info()['state'] == 'PENDING':
print('Cluster is Pending Start')
time.sleep(60)
elif get_dbrks_cluster_info()['state'] == 'RUNNING' and not cluster_restarted and not started_terminated_cluster:
print('Restarting Cluster')
cluster_restarted = True
restart_dbrks_cluster()
else:
print('Cluster is Running')
await_cluster = False
What is this doing? Well we’re using a Python “while loop” to constantly hit the REST API to return us the status of the Cluster. If it is “Terminated” we attempt to start it, if it is “Pending” or “Restarting” we wait 60 seconds then try again, finally if we get a state of “Running” we either restart the cluster if we have not already done so or exit out of the while loop. In case of erroring, there is a 20min time out, so if the cluster never gets to a running state in that time an error is thrown
Upload Notebooks
So now we have a working cluster, we want to upload some Notebooks to Databricks.
To run you will need
1) Azure Databricks Workspace URL
2) DBRKS_REQ_HEADER (detailed above)
dbrks_create_dir_url = ['DBX_WORKSPACE_URL'] + "api/2.0/workspace/mkdirs"
dbrks_import_rest_url = ['DBX_WORKSPACE_URL'] + "api/2.0/workspace/import"
def createFolder(resturl, restheaders, folderpath):
print(f"CREATING FOLDER: /folderpath}")
response = requests.post(resturl, headers=restheaders, json={"path": f"/)
if response.status_code == 200:
print(response.status_code)
else:
raise Exception(response.text)
def writeFile(resturl, restheaders, localpath, folderpath, file):
fileLocation = localpath + "/" + file
import base64
data = open(fileLocation, "rb").read()
encoded = base64.b64encode(data)
files = {"content": (fileLocation, encoded)}
if ".py" in file:
fileName = file.split(".")[0]
fileName = fileName.replace(".py", "")
print(f"UPLOADING FILE: /folderpath}/")
response = requests.post(dbrks_import_rest_url,
headers=DBRKS_REQ_HEADERS,
files=files,
data={'path': folderpath + '/'
+ fileName, 'language': 'PYTHON',
'format': 'SOURCE', 'overwrite': 'true',
'content': encoded})
if response.status_code == 200:
print(response.status_code)
else:
raise Exception(response.text)
The above creates all folders and subfolders required, before uploading the Notebooks themselves. If the folders and/or Notebooks already exists this code will simply update them. Unlike when working with Clusters, if this process fails we will know straight away in the form of a 4xx or 5xx error, so there is no need for additional functionality to monitor this. This is because we are uploading the Notebooks as part of a REST POST, so the functionality is all part of the REST action itself
Summary
The above are starter scripts and pipelines to help get going with DevOps for Databricks via the Databricks REST API. I advise you to explore the REST API further if you wish to expand on the functionality
All code demonstrated is available in more details as part of this Github repo: https://github.com/AnnaWykes/devops-for-databricks. Please note, the code in this blog has been greatly simplified, and the repository is subject to updates, so you may find some differences, but the core architecture and principles are the same. Feel free to reach out with questions!
In the next blog we will explore how to put all of the above Python Scripts into an Azure DevOps (YML) pipeline