



It seems these days that every person I talk to is either a scientist, engineer or architect, we’re fairly obsessed with aligning our technical roles to respected professions that denote the amount of education & training that go into it – and that’s fair given how much time & effort goes into attaining these roles… but it really doesn’t help us define them. The data engineer is an emerging role that’s rapidly growing in popularity… but what is it?
I know I’m going to get some backlash for referring to the role as emerging, “it’s been around for years” some people cry. But I don’t agree; I think there was a very specific function that was heavily tied into data science that has evolved in the past two years into something new. There’s a second camp that will be booing and shouting “It’s just an ETL developer”, but again, I don’t think so. Hear me out.
It’s not always the most accurate indicator, but a quick glance at google trends sees Data Engineer rocketing in popularity, compared to more traditional functions such as BI and ETL Developer:

Now, that’s not saying that the other roles are going away, not by a long stretch. If we take a look at the “skills” listings on LinkedIn, we see a story of the rising underdog; far more people list Business Intelligence as a skill than Data Engineering, but the growth rate of the latter is impressive:

Figures acquired from LinkedIn Analytics on 02/07/2019
There is a huge number of people who consider themselves skilled in BI, with only a tiny fraction of that number professing to be a capable data engineer – but it’s growing at a massive pace. That’s why I’m calling it “emerging” – it’s not yet mainstream and it’s undergoing flux in its definition, but it’s growing at a significant rate… but what is it?
The Data Science Engineer
Let’s start with the original idea of the Data Engineer, the support of Data Science functions by providing clean data in a reliable, consistent manner, likely using big data technologies. I’m going to refer to this role as the Data Science Engineer to differentiate from its current state. Data preparation is a fundamental part of data science and heavily tied into the overall function. We can see this on Monica Rogati’s Data Science Hierarchy of needs:
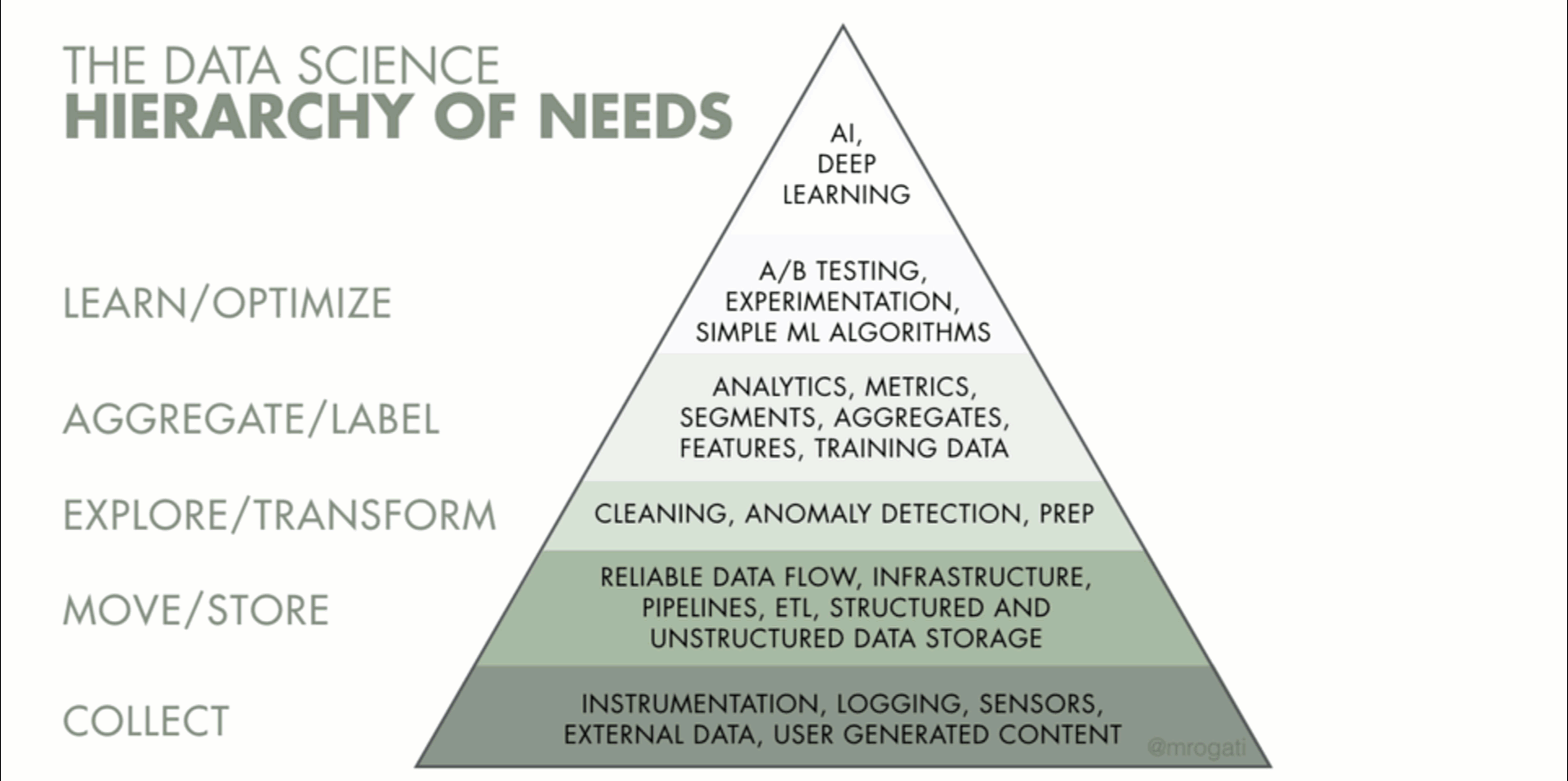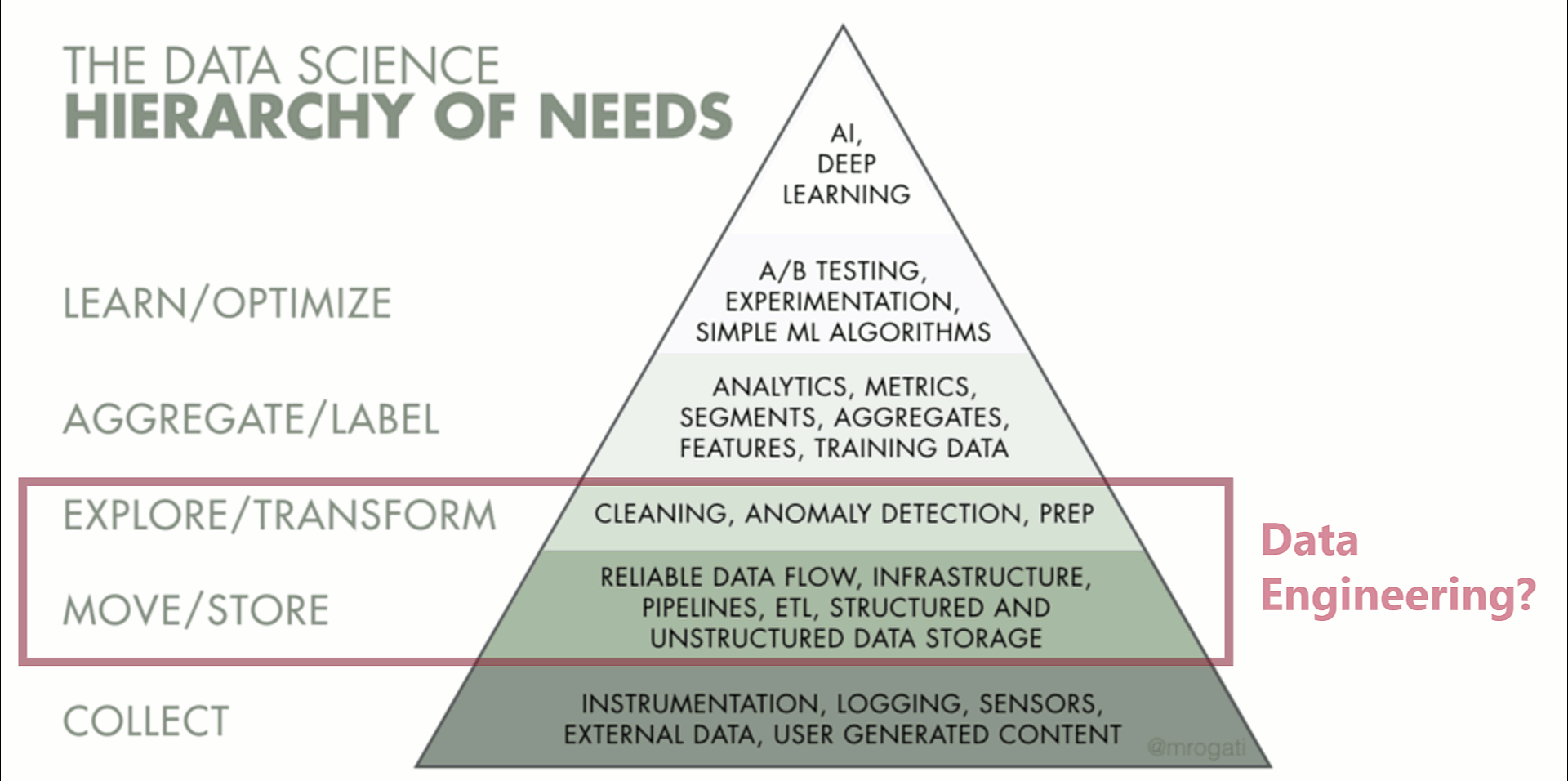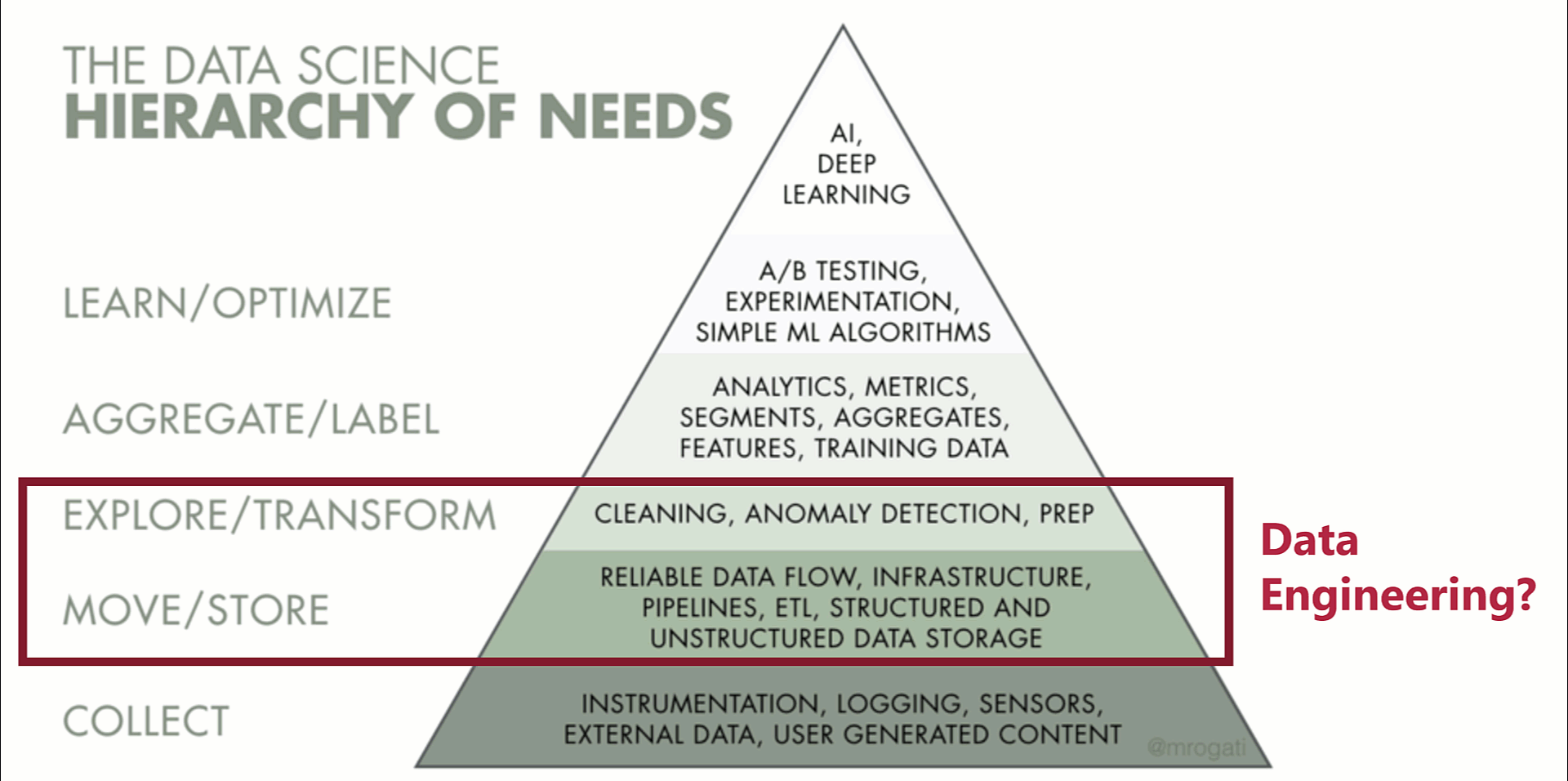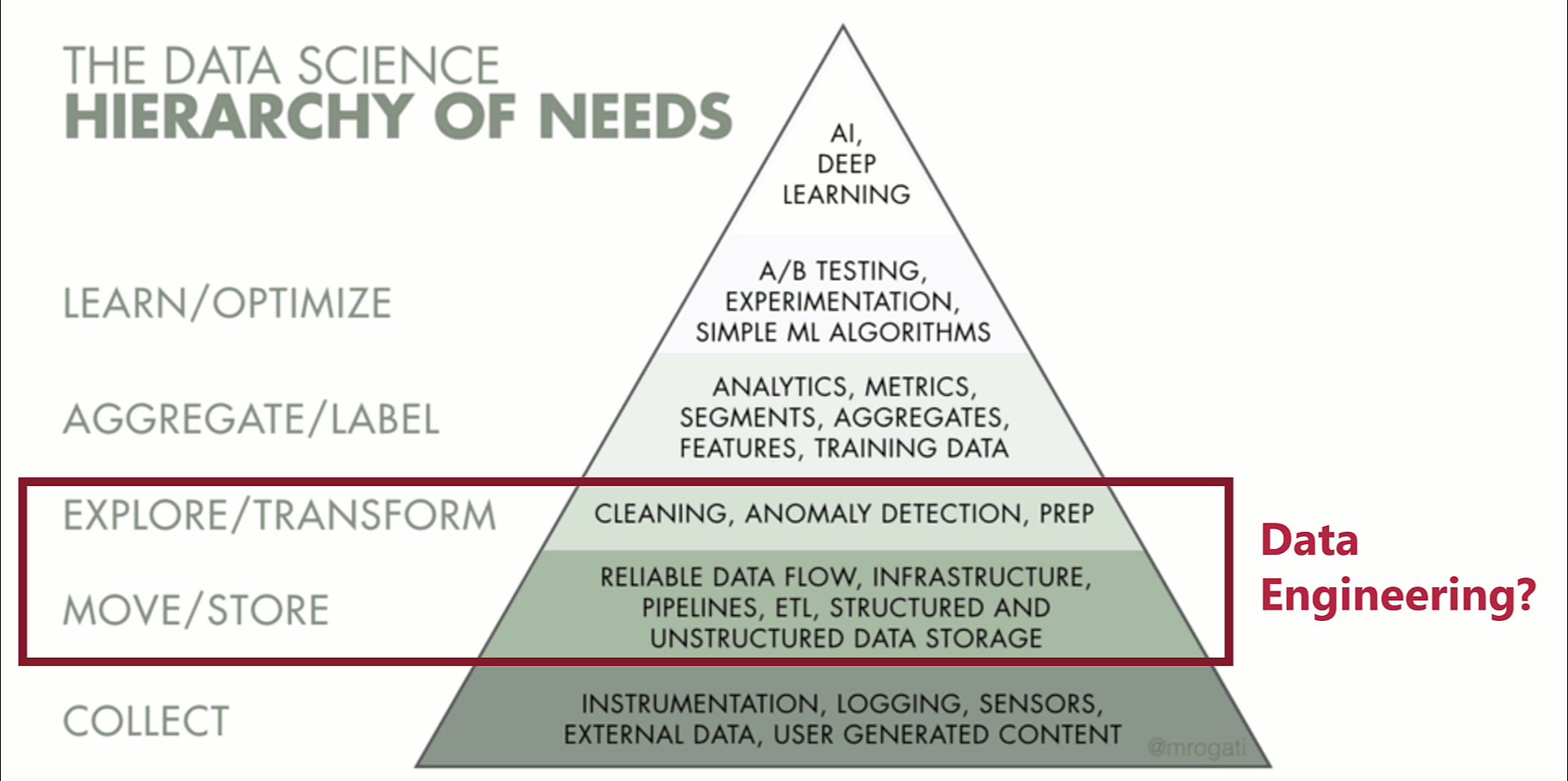
The Data Science Hierarchy of Needs Pyramid, “THE AI HIERARCHY OF NEEDS” Monica Rogati
Moving and storing data, looking after the infrastructure, building ETL – this all sounds pretty familiar. We might even extend this definition to cover the “COLLECT” layer and even some of the “AGGREGATE/LABEL” layer, that’s not the point I’m trying to make. The tasks described here likely tick a lot of boxes in what we consider Data Engineering to be… but I think it over simplifies things somewhat. I certainly know a few data engineers who would be fairly offended to be relegated a support function propping up the higher level data science elements.
Evolution of the Data Engineer
If that’s what is used to be, and it covers many of the functions that we expect it to, why am I arguing that it’s evolved?
For me, it’s the coming together of several disciplines as technology has evolved – the “data science engineer” is just one of those disciplines.
ETL Developers
As the cloud has taken off, a lot of the big data technologies originally only in the realm of specialists have become more mainstream. Every data warehouse I build these days has a data lake layer – even in its most simple form, it adds massive benefits – but this means I’m adding Apache Spark processing, I’m storing data across distributed file systems (HDFS) but I’m doing it through platforms such as Databricks and Azure Data Lake Store, which provide a simplified abstraction layer. In short, the technical barrier for adopting these tools has been lowered dramatically.
This means that the business intelligence function of “ETL Developer” is finding itself faced with this new selection of technologies and the rich history of big data architectural patterns and pitfalls they need to learn. But just as they are facing challenges, they bring with them a set of data warehousing patterns, modelling techniques and additional customers they need to serve. They need to understand master data management, slowly changing dimensions, building flexible models that must pre-empt what questions might be asked, rather than a dataset for a specific machine learning model. If you’re not convinced that things like Kimball have a place in the modern data warehouse, I’ve put my thoughts down here.
UPDATE: One great comment I’ve had is how the ETL developer thinks differently about scale. The ETL developer has a fixed capacity box and an available time window to fit everything inside, whereas the modern Data Engineer has both scale up and scale out parallelism in their toolbox, which they need because data volumes and demands are much more varied. Props to @ike_ellis for the suggestion.
Software Engineering
Then we have the other side of the development fence – Application Development/Web Development has long been powering ahead of the data development community. I’m still encountering BI teams that haven’t yet adopted agile as a project management methodology, whereas you’ll be hard pressed to find that in wider development circles these days. I’ve worked with several software engineers who decided to jump across the fence and work with data, only to find the development culture to be akin to software development ten years ago.
I remember when it clicked for me, a good few years ago now – I was having a beer with a group of friends, all of them developers, all of them killing it in their fields. I was there as the token “Data Guy” and occasional butt of any “not a real developer” jokes. They talked back and forth about designing around microservices, parallel dev workstreams and whether TDD (test driven development) is applicable to every single development style. I sat there thinking about the giant monolith SSIS packages I had, the lack of code separation, the overall code footprint and it slowly dawned on me how behind we were. The fact my development cycle was measured in months, not days was a real eye opener – and it’s a big part of how I design data platform solutions these days.
For me, the shift to the cloud has been a fantastic opportunity to challenge the traditional ways of working, to learn from software development and apply many of their techniques. Some of them will work, some of them won’t but we should always be challenging and trying to improve.
In my opinion, that’s a very important part of the data engineer today – the solutions we’re building are expected to be agile and reactive to change, to be robust and resilient, to be integrated into Continuous Integration/Continuous Deployment pipelines… basically they’re expected to be well engineered.
The Full Mix
In reality, it’s even more complicated than a three-way blend of previously known roles – there’s elements of BI development, a lot of Big Data dev and even elements that would previously be the domain of Data Mining experts. I made a quick visual of these various roles and how we see them represented today:
Today’s Data Engineer
Where does that leave us? We have a role that has evolved from the convergence of a range of previous specialist roles and they’ve brought all their traditional customers with them. The data engineer is providing data in specialist formats for data scientists, traditional warehouse consumption and even for integration into other systems. They’re expected to understand modern software development and to be well versed in a range of programming languages & tools… it’s a demanding role.

But note… it’s not everything that we expect a Business Intelligence developer to be. We’ve not talked about semantic models, about dashboard design, about teasing out KPIs from business workshops. We’ve not delved into the murky world of self-service reporting and governance. These skills aren’t being taken up by the data engineer, it’s more a separation of the “data preparation” part of the BI developer and enhancing it with data science support and good software engineering.
We’ll post more in the future about how to become a data engineer; what skills are required and where it looks like the industry’s going. But before you can understand something, it’s always helpful to know where it’s come from, and this intersection of skills is how I’ve come to understand it.
If you want to more about becoming a data engineer, I’m delighted to be helping deliver part of the Leaning Pathway “Becoming an Azure Data Engineer” at PASS Summit 2019 later this year, as well as delivering an in-depth “Engineering with Azure Databricks” full-day, pre-conference training session.
If your team is looking to undertake a modern data warehouse project and the idea of data engineering is daunting, Advancing Analytics offer a tailored MDW bootcamp, teaching you the skills you need to succeed.
If you’d like to know more about augmenting your warehouses with lakes, or our approaches to agile analytics delivery, please get in touch at simon@advancinganalytics.co.uk or visit www.advancinganalytics.co.uk to learn more.
Till next time.
