




Thanks for continuing to read my series on applying DevOps to Machine Learning. If you’re new here you might want to start at the beginning or check out some technical content. Both should help make this all easier to digest.
So let’s remind ourselves of what we are trying to achieve. We are looking to apply DevOps to Machine Learning, to remove the need to have a data engineer. We want to use automation where we can, CI/CD and a load of tools all working in harmony to achieve this. We have focused on a lot of the theory for the last few blogs, and this is no exception. The next blog is the detailed how to. So keep reading.
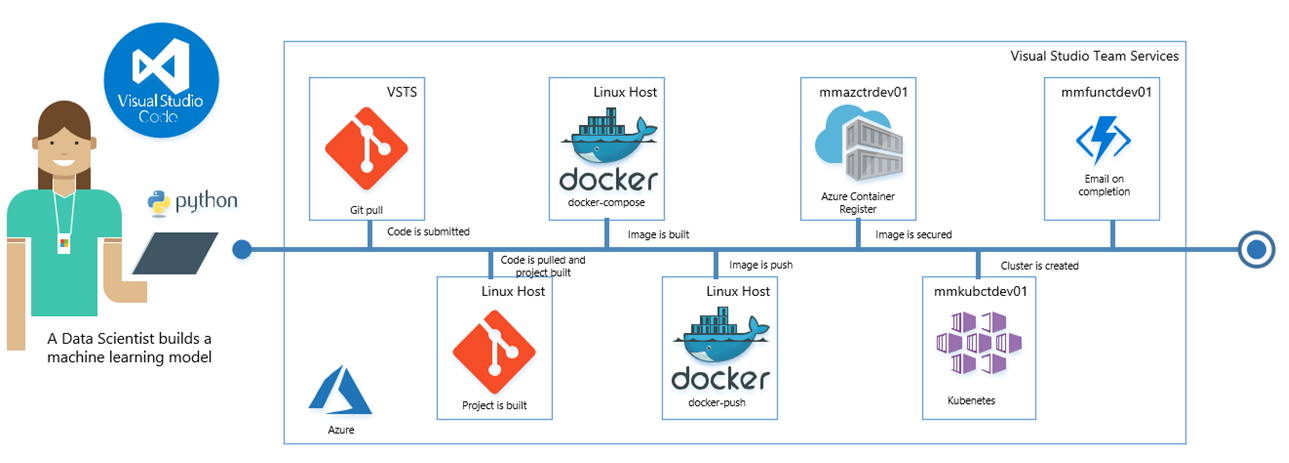
Based on the my research and a review of existing books and blogs on this topic, I will implementing the following DevOps techniques to reduce the difficulty of promoting a model in to production.
-
Source control
-
Infrastructure as code / Configuration as code
-
Continuous integration
-
Continuous deployment
-
Microservices & Containers
-
Monitoring and lineage
I have limited the scope to services which are in Azure, however as Azure supports IAAS servers, I could install any Apache open-source tool. The design principles restrict this as one indicates the need for PAAS over IAAS. As Azure is vast, even when working under restrictions, there are still multiple options which could work. The following sections indicates the tools I will use and the decisions I made during the selection process.
Source Control for machine learning
The use case in this blog series will be using a variety of tools in Azure (although everything you see here can be achieved with other vendors). To make my life a little easier, the source control used will need to be something which ties in well with Microsoft Azure. There is also the requirement to be able to source control files both for configuration of the infrastructure but also for the data used to train the model and part of the data which will be held back as a private testing dataset. Microsoft has its own source control solution call Team Foundation Services (TFS) (Microsoft 2017b). TFS works very well for traditional software development on an on-premises development. All development will occur in Azure, so I require a tool which works both on premises and in Azure.
Azure resources typically supports three main source control solutions, TFS, Git and Github. The consistency of Microsoft’s implementation is patchy at best. While most tools support Git, there are a few which only support Github. Git is the primary tool which is supported by most tools in Azure. Git is also a really nice tool and my preferred tool on all projects.

Tool selected – Git
Git is more than enough for this project. To ensure that the source control remains clean and organised through this project I will implement the following standards. Have a solid standard from the onset will help you find what you are looking for. The worst kind of source control is one which is a dumping ground for code. That is where DevOps goes to die – Try automating deployments when you cannot find anything. So a few tips:
-
Each solution will be in its own folder
-
Each solution will be logically named (ModelManagement.AzureFunctions)
-
All build automation tools will remain their own folder
-
Every resource in Azure will have a corresponding deployment script
Git supports branching and merging of code from the origin repository. To keep my code clean I will be using a master branch, a development brand and feature level branches. The intention of doing this, is to ensure that a new development on a feature does not break the main code base. Once development has been completed, each branch will be merged back in to master, where a release branch will be setup. This release branch remains separate from the main code base.
We will need to store the training data in Git. This is fine, but looking for changes in data is difficult. If this data has changed between training and deployment, the model could lose accuracy. This is something that I am still working out. I don’t think that source controlling data is a good idea, but at the moment there doesn’t really seem to be a good alternative. You could version the in a data lake, however that relies on the user remembering. Why are you source controlling data!?! I imagine a few of you might be thinking this, and I agree, as a software developer this feels odd, however a machine learning model can be improved without making any code changes. By adding more data, more clean data, our model can improve, it can also degrade. If you want repeatable results then we need a copy of the data.
Infrastructure as code for machine learning
A key component in DevOps is infrastructure as code and configuration as code. Being able to ship code alongside the right configured hardware is vitally important to the success of a deployment. This is a very common challenge in industry and there are many tools covering a variety of infrastructure challenges.
However, the machine learning/analytics area is noticeably behind other technical areas such as Web and Application development. Within the Azure environment, Resources can be manually deployed or deployed/configured using the Azure Resource Manager (ARM) templates. Even when using the manual Azure Portal, any configuration commands are sent to the ARM service using a specific template – this makes it super simple to build something once, download the template and keep it for reuse. We therefore need a tool that integrates well with these ARM Templates (Microsoft, 2017c). I have limited the choice to three options, Terraform, Ansible and ARM template manager – There are others on the market, however these 3 are widely used for Azure. .
Terraform is a cross-platform tool developed by Hashicorp which is rapidly becoming the tool of choice for many development software vendors (Terraform, 2017). It allows for a common approach to be adopted across any of the more popular cloud providers. The main functionality allows for a solution to be defined then sent to the various APIs to be updated. Each provider has a suite of available templates – unfortunately, a lot of the components required for this project are not yet supported by Terraform.This is not a shortcoming of Hashicorp and Terraform, this is the nature of Azure. Things move fast and we need to move with them. It is difficult for vendors to keep up. Terraform can be developed to deploy generic ARM templates, however it does not support updating or deleting components, which will be required when rolling out updates to our models.
Ansible, another common open-source infrastructure automation tool, Ansible is particularly good at designing deployment pipelines using a graphical workflow Interface. However, Ansible suffers from the same issue as Terraform in that it does not cover the templates that is required for Infrastructure-as-code for machine learning.
Azure Building Blocks is a new tool, released by Microsoft during October 2017, which wraps ARM Templates within a lightweight configuration tool to simplify the deployment process (Microsoft, 2017d). Unfortunately, given it is a very early release, the Azure components covered by the tool is very restricted. The final option is to rely on classic ARM templates. The ARM service, when presented with a configuration file and parameters, will automatically take care of creating new components, updating the configuration of existing ones and deleting components that are no longer part of the specified configuration – this is most of the complexity involved in managing infrastructure as code deployments. One caveat with ARM templates is that the need to deploy everything to a single resource group.
Tool selected – ARM Templates

In source control, there will be a section from ARM templates and each template will have a corresponding parameter file and a deployment file in PowerShell.
Configuration as code for machine learning
There are loads of options for configuration as code, however we want this to be simple and repeatable, which leaves us with only two options, virtual machines or containers. One of the problems with machine learning is the loss of accuracy when a model is put in to production. This is typically caused by differences in configuration on the machine in which the model was developed. An example of this might be the version of Python a data scientist is using, and then also the version of each library they are using. This is typically not tracked by a data scientist, they are less concerned about sklearn version 15 or 16, if it functions.
Virtual machines take too long to configure and would always be an IAAS solution – Our preference is PAAS. Why? Because we want to focus on the development of a model and not the time spent configuring servers.Therefore we need to select a series of tools which will enable containers as paas.
Tools selected – Docker, Kubernetes & Azure Container Registry
Using a virtual machine is possible, but would be difficult to achieve the end-to-end pipeline with it. Docker makes this process easy.
Docker – A Docker image is made up of three files, the requirements, the DockerFile and the application code. This is at a minimum for deploying an application. You can load as much as you need in to the Docker image. Each part can be source controlled with Git. Azure has Paas support for Docker and it is locally supported on both Windows and Linux machines. If you’re new to Docker I will have a seperate blog on getting started using Docker for Machine Learning. For now you can go and look at the Docker website. https://www.docker.com/
Kubernetes – One of the design principles is for elastic scaling. We need our machine learning model to scale. As demand increases we need to ensure that the load is balanced, if we need more nodes to run our models on we need a simple way to do this. In Azure, Docker images can be run in a Kubernetes cluster, which has elastic scaling. When I first looked at Kubernetes, I could not see how to issue a Docker command to build to Kubernetes, this is because Kubernetes does not work with DockFiles it works with Docker images. Kubernetes is great, as demand increases and more images are required, Kubernetes can be configured to will add more. As throughput increases, more nodes will be added to the cluster – fantastic. I will have a blog on this shortly. You can read more about Kubernetes here https://kubernetes.io/ .Kubernetes can be installed on any server, however we are striving for platform-as-a-service. Azure has a feature which (at the time of writing) is in public preview. Azure Container Instances (managed) (AKS) – https://azure.microsoft.com/en-gb/services/container-instances/.
Azure Container Registry – Kubernetes uses docker images, so we need somewhere to store all these images. Docker has its own public repository but we will want to keep these private. Azure Container registry is a private container repository in Azure. https://azure.microsoft.com/en-gb/services/container-registry/

Continuous integration for machine learning
For traditional software development, there are a variety of tools which can be used for continuous integration, however many of these tools are not suited to machine learning. What we are trying to do is relatively new. There are elements which share integration steps between software and machine learning, however for a lot of what is required, we will need to develop custom integration scripts. Examples of continuous integration tools include, Team City, Jenkins, GitLab and Microsoft’s Visual Studio Team Services.
As indicated in the DevOps summary there are three main tests that need to be completed by a continuous integration tool.
-
Item level testing
-
Acceptance testing
-
Integration testing
Testing a machine learning model is different to testing a piece of software. In most cases we have a solution so we can build that solution to check that there are no missing dependencies, however unlike testing a stored procedure where we can use a testing framework such as test-driven-development, this is not possible with a machine learning model. When we are testing, we will be looking to score the data on a set of data that the model has never seen before. Integration tests will show that we have all the elements in source control to deploy our machine learning environment.
Tool selected – VSTS & Custom PowerShell
A lot of what is required from a testing perspective will need to be created from scratch and will be language specific. For this project I have limited the scope to only look at Python models, therefore the model testing will be executed by running a Python model. I will use VSTS to orchestrate the testing as this has a cloud build agent (service which executes the build steps – free to use up to 240 hours per month), this is one less server which needs to be maintained. VSTS is also where I have the backlog of work and also Git. By having VSTS and Git connected testing pipelines will be executed when a commit is made against the development branch – Cool huh!
Continuous delivery/deployment for machine learning
A lot of the complexity of this project is focused around continuous delivery. As a model is source controlled, we are aiming to push that model in to Azure and exposing it via a REST API. We want this all to happen in one process! This requires the combination of many moving parts and disparate Azure Resources.
Most of the comments made relating to infrastructure as code as also applicable to the deployment of machine learning model. Deployment is the process of taking a series of actions, first by taking the latest version of the code from Git and then moving step-by-step completing the required setup of resources in Azure.
Exposing an API – Scully discussed an option deploying models using a REST API (Scully, 2015). The option offers any system which can call a REST API the ability to work with the deployed machine learning model. The model being used a test throughout the development is a classification model in Python. Python has the ability to deploy an API using Flask. We will look at a few different techniques for getting our result from our python model. My preference today is to stream the data. This is advocated by Dunning and Friedman in Machine Learning Logistics. You can read a summary of this book here.
Tool selected – VSTS & Custom PowerShell
VSTS supports in-built and custom extensions for building and deploying our models to Docker and Kubernetes.
Monitoring when in production
When a model is in production, telemetrics are required to see how the model is performing. The easiest way to control this is to have the model persist operational metrics about its running in to a data store. In Azure, there are numerous data stores. Our models need to be globally available and globally scalable. As demand increases our models need to be able to scale. This is one of the core design principles. we have a few different options:
Paas SQL Server Database / Iaas SQL Server VM – SQL Server supports many large applications. Azure has several options , the first is a Paas option which has different prices depending on demand, this is a cost for usage and does not require any additional licences. The alternative is an Iaas virtual machine running SQL Server. With this option you can either bring your own licenses and pay for the compute or pay for the whole VM with SQL Server. One of the design principles is Paas over Iaas, SQL Server on a VM would not be suitable for a machine learning data store. SQL Server is queried using SQL, considering 56% of data scientists are familiar with SQL this would be an easy option for data storage and metadata (CrowdFlower, 2016).
An alternative option would be CosmosDB (formally DocumentDB). CosmosDB is a global scale document store. The skillset required to develop for CosmosDB is not typically found in a data science team, it is normally the responsibility of an engineering team. CosmosDB is queried using JavaScript and can be modified with PowerShell. SQL Server is an option, however a core principal is global scale, which SQL server cannot offer. It is not so much of a concern as to the skills required to maintain this store, as the contents will be exposed by a reporting application.
Tool selected – CosmosDB & Power BI
CosmosDB is the most versatile option available in Azure. CosmosDB is a global scale application which will grow to meet the demands of the data science environment (Microsoft, 2017e). PowerBI will be used to expose telemetric reporting back to the data scientist and operations. Power BI is Microsoft’s flagship business intelligence tool. The reason I have selected it for this use case is its ability to have both static datasets (updated when queried) and streaming dataset (always updating). The allows for a real-time view of what is happening in our machine learning environment.
Other tools available
There are many tools which could also be used for any part of this project. The aim however is to make a product which is simple to use and does not require the user to be a data engineer – while difficult, I feel this is achievable.
Thanks for reading. Next we look at a few introduction and videos on how to use Docker, Azure Container Registry, Python and Kubernetes for Data Science. Then show the real nitty gritty code. I promise. Theory is almost done.
