



What is Microsoft Fabric?
Fabric is Microsoft’s shiny new all-encompassing Software-as-a-Service (SaaS) analytics platform. That means Fabric is your one-stop-shop for your full data platform, from ingesting source data through to data visualisation across each persona, from Data Engineer to Power BI user and everyone in between.
It brings together Azure Data Factory, Azure Synapse Analytics and Power BI into a single cohesive platform without the overhead of setting up resources, maintenance, and configuration. You can stand up a complete end-to-end analytics solution in little time with all capabilities baked in, from Data Integration and Data Engineering to Data Science, and real-time analytics.
With Fabric, Microsoft are ambitiously embracing the Data Lakehouse architecture in a Mesh-like vision. OneLake is the key enabler of this architecture and the capability to organise data with ‘Domains’ and ‘Workspaces’. It will be interesting to see how this plays out for customers, given the biggest hurdle for Mesh architectures is the people and process, not the technology.
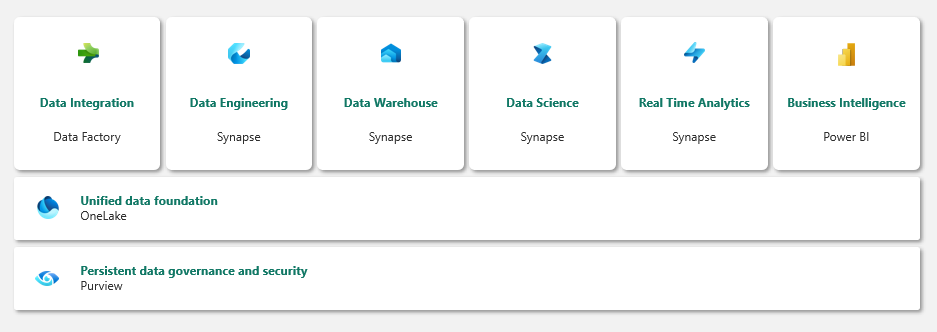
There are a number of workloads available for use within Fabric which enable you to stand up an end-to-end analytics platform.
OneLake
Everything in Fabric is built on OneLake which Microsoft are describing as “the OneDrive of data”. OneLake comes out of the box with every Fabric tenant and is the home for all your data, moving away from data siloes and the need to copy data to where you need it. Under the hood it is still Azure Data Lake Storage Gen2 but there is so much more to it than that.
What are the key features of OneLake?
Open Formats (Delta!)
The first thing to talk about is that OneLake supports Delta Lake, which is the foundation of a Data Lakehouse platform. This is amazing news as Delta Lake is an open-source format which means there’s no vendor lock-in with Fabric and many other tools and technologies can work with the data in your OneLake. Data can be stored once and used where it is. All of the different engines within Fabric use Delta, giving you a consistent foundation and reducing the need for format changes.
OneLake is essentially just Azure Data Lake Storage Gen2 under the hood which means it supports existing ADLS (Azure Data Lake Storage) Gen2 APIs and SDKs giving you the ability to hook up existing applications and tools to a OneLake endpoint.
Various layers make up the security model for OneLake, access can be controlled directly on top of the lake as well as via 'workspaces' which act as containers over the lake which can have their own policies defined. There is also the ability to control access via each of the compute engines within Fabric to give organisations more control over their data. We’ll explore best practices for this in a later post.
Fabric Workloads
Fabric has several distinct experiences across the platform which have been designed around specific user personas. There are multiple ways to achieve the same outcome, it all depends on the skillset and preference of the user. Each workload has artifacts relevant to the specific capability which we’ll explore below.
Data Engineering
The Data Engineering workload has some great features for Data Engineers to work with. Here we can see the first mention of a Lakehouse within Fabric, a Lakehouse artifact lives within its own workspace folder within the lake and allows data processing using the Spark engine. This workload allows us to work with Notebooks and Spark, which is a key feature for Advancing Analytics. The Spark engine is a fantastic tool to automate data processing through dynamic, metadata driven processes.
Any code that is executed within a Notebook will run on a remote Apache Spark pool and from here you will be able to see a real-time progress indicator which details the execution status. This provides us with useful information that can be used to aid optimisation of our queries and workloads.
Within the engineering workload we can create the following artifacts:
-
Lakehouse
-
Notebook
-
Spark Job Definition
-
Data Pipeline
Data Engineers can use Notebooks within Fabric to ingest and transform data and they support the following languages:
-
PySpark
-
Spark
-
SparkSQL
-
SparkR
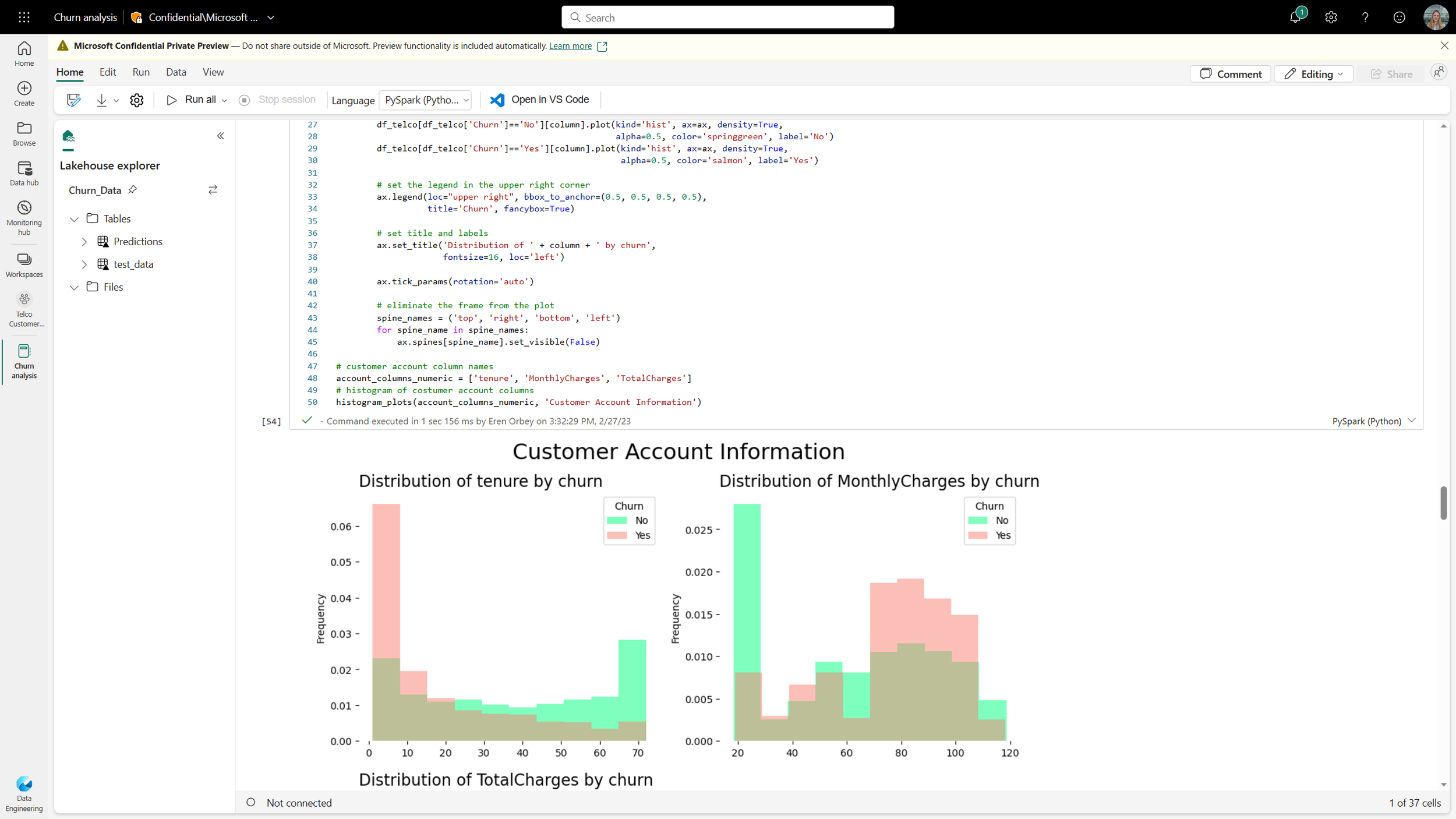
Data Engineers can work with Spark notebooks in various languages to perform transformations on data.
Data Integration
Dataflows and Data Pipelines are key components of data integration workloads within Fabric. Dataflows, which use the Power Query experience, offer a low-code solution for data cleansing and transformation tasks. This will be very familiar to people used to using the Power Query editor within Power BI. Dataflows can be scheduled and integrated with data pipelines so in theory you could have people with domain knowledge transform some parts of your data and then schedule it as part of a wider pipeline process.
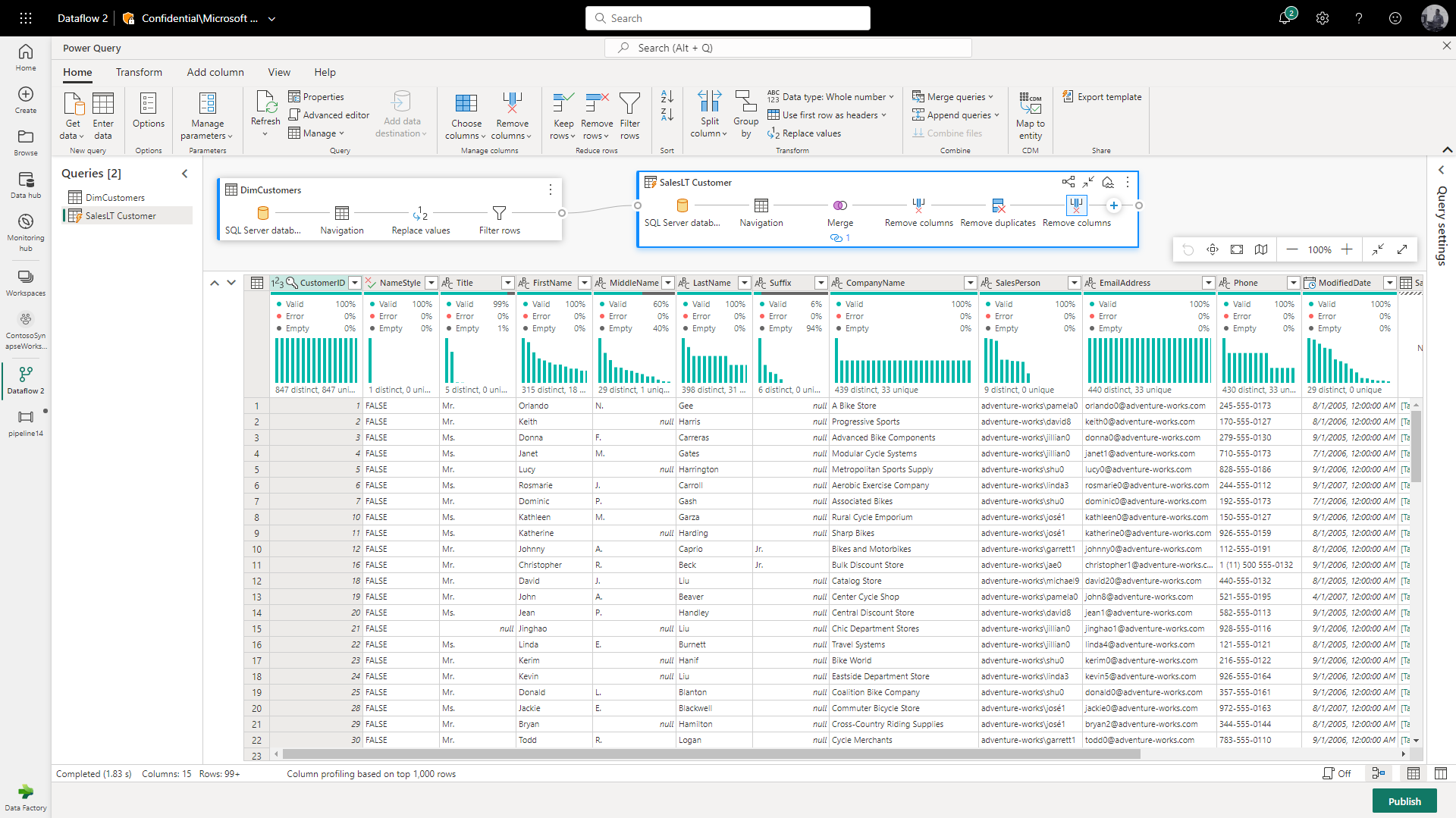
Data can be transformed using code free transformation with Data Flows.
For those more familiar and at home with Data Factory or Synapse pipelines you can create pipelines in a similar way to how you normally would. For anyone newer to data integration, Data Factory offers a low code solutions to build an ETL/ELT process. A small feature that is missing is the ability to paste in JSON code into the pipeline experience, so this is a bit of a limitation if you wanted to copy some existing ones over.
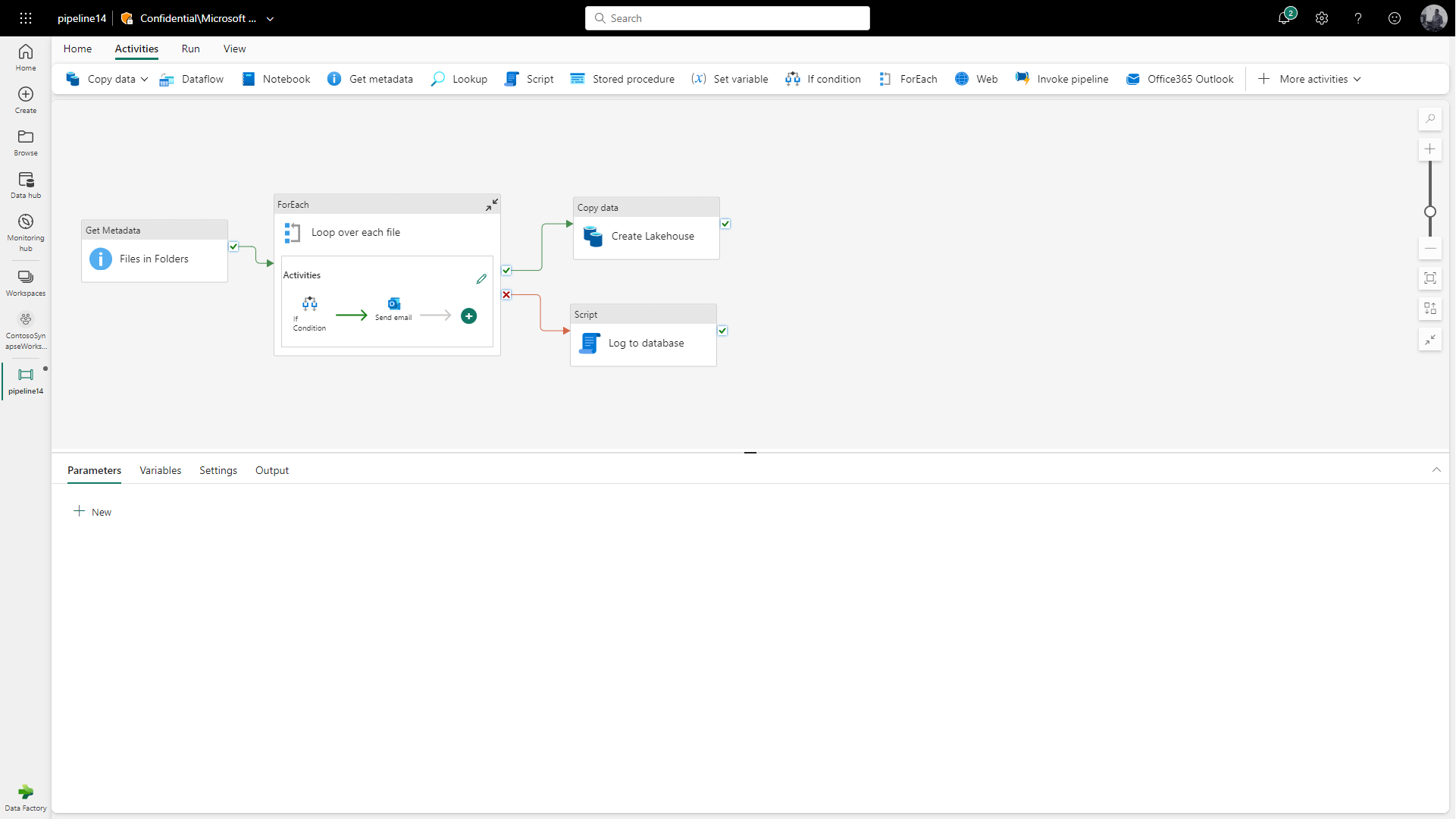
Engineers can work with pipelines in Data Factory which is a familiar experience coming from Synapse pipelines/Azure Data Factory.
Data Warehousing
Data Engineers and analysts can take advantage of relational data warehousing capabilities within Fabric. Behind the Warehouse is a unified SQL engine which is serverless and dedicated combined to offer the benefits of separate storage and separate compute capabilities. This is an improvement made from Synapse in which these capabilities are separate. Warehouse functionality has full T-SQL capabilities but can also read and write Delta format providing cohesion and consistency with the rest of Fabric. Something key to point out here is that this is a Lake-centric database which differs from the traditional operation of a Datawarehouse.
There are two key concepts here; SQL Endpoint and Warehouse. The SQL endpoint is an artifact automatically created by loading data into a Lakehouse as a Delta table. It is also important to note that T-SQL statements will fail on the SQL Endpoint artifact, so it is important to understand the differences here.
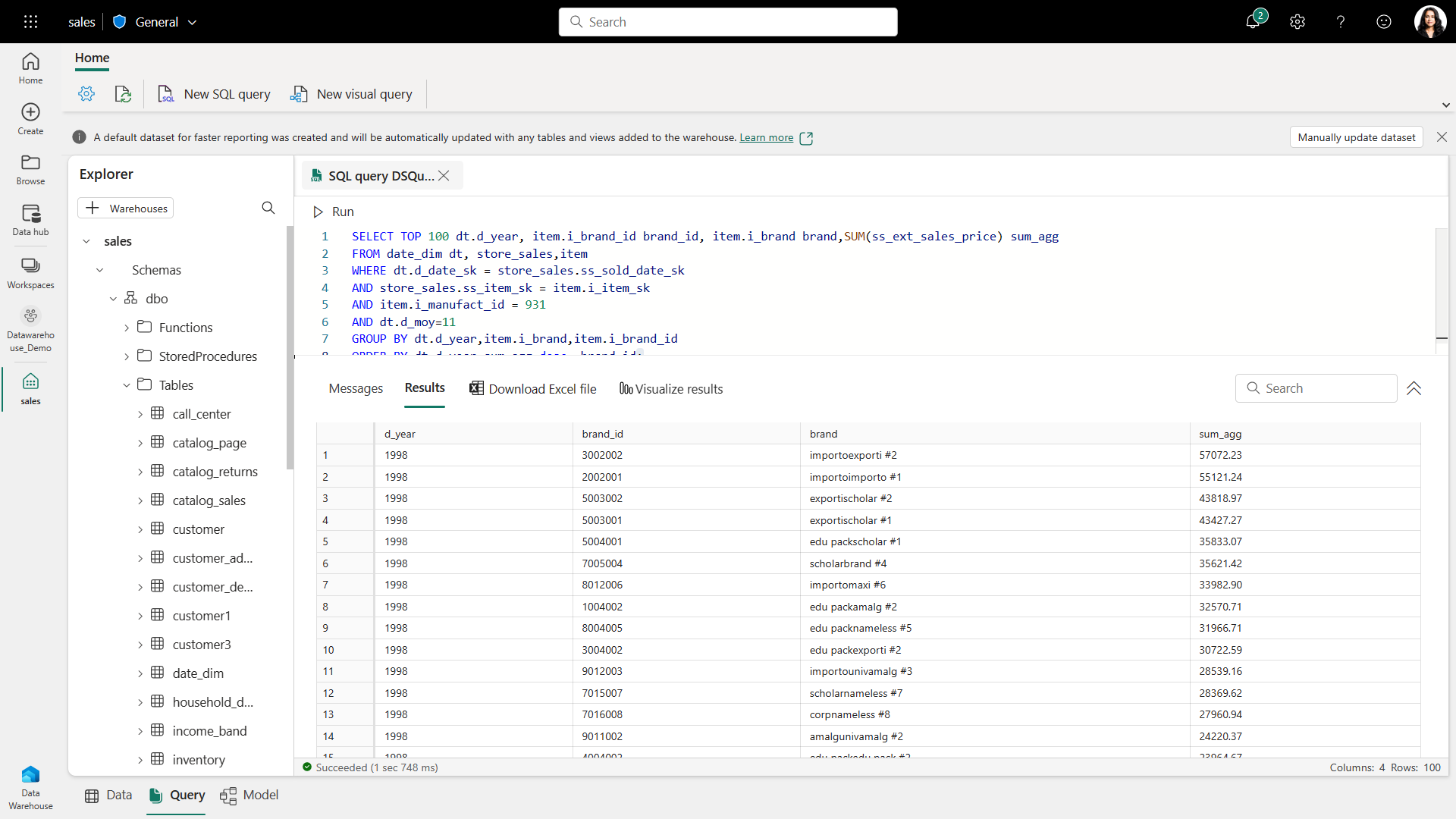
Data can be transformed within the Data Warehouse artifact using SQL.
Real-time Analytics
Kusto Query Language (KQL) is the foundation of real-time analytics within Fabric. It allows high volume data analytics across a wide range of structured and unstructured data. Kusto can be used to query a variety of data types such as IoT (Internet of things) logs and time series data. One of the key benefits of using Kusto is the ability to load vast amounts (petabytes) of data within seconds. It is an interesting choice of query language as this isn’t as well-known as SQL for example, this will add an element of upskilling in both citizen and pro-developers in some places. However, this has been done to be able to query increasingly larger datasets.
Within the Real-time Analytics workload we can create the following artifacts:
-
Kusto Database
-
KQL Queryset
-
Eventstream
Real-time analytics are managed with KustoDB and query sets, they can handle huge amounts of data.
Data Science
Fabric provides a variety of data science tools, including machine learning experiments, models, and notebooks, to support users throughout the data science process. The key features of Fabric are described below in terms of a typical data science process.
Business Understanding
Fabric is a unified platform that facilitates collaboration between data scientists, business users, and analysts, enabling them to better understand the business context and define the objectives of machine learning projects.
Data Acquisition
Users can interact with data stored in One Lake using the Lakehouse item, easily attach Lakehouse to a Notebook, and read data from it. Fabric also provides powerful data ingestion and orchestration tools through data integration pipelines.
Data Preparation & Cleansing
Fabric offers tools like Apache Spark to transform, prepare, and explore data at scale, Data Wrangler for seamless data cleansing, and Notebooks for data exploration, making it easier to prepare and clean the data for machine learning models. This also ensures that high-quality data is used for model training, which in turn improves model performance.
Model Training & Experiment Tracking
Users can train machine learning models offers the capability of using SynapseML and Spark MLlib libraries in addition to other popular libraries like Scikit-Learn. SynapseML, formerly known as MMLSpark, is an open-source library designed to simplify the creation of scalable machine learning pipelines, while Spark MLlib is a part of the Apache Spark framework that provides scalable machine learning algorithms. Both SynapseML and Spark MLlib enable users to leverage powerful and scalable machine learning capabilities within the platform.
Fabric also utilises MLFlow, an open-source platform that streamlines the machine learning lifecycle, offering tools for tracking model training and managing models, leading to a more efficient and organised ML workflow.
Model Scoring
Users can perform batch scoring of machine learning models in Notebooks to score a model which can also be written to OneLake and consumed in PowerBI reports using the PowerBI “see-through”-mode. This ensures that insights derived from models can be effectively communicated and utilized within the organization.
Business Intelligence
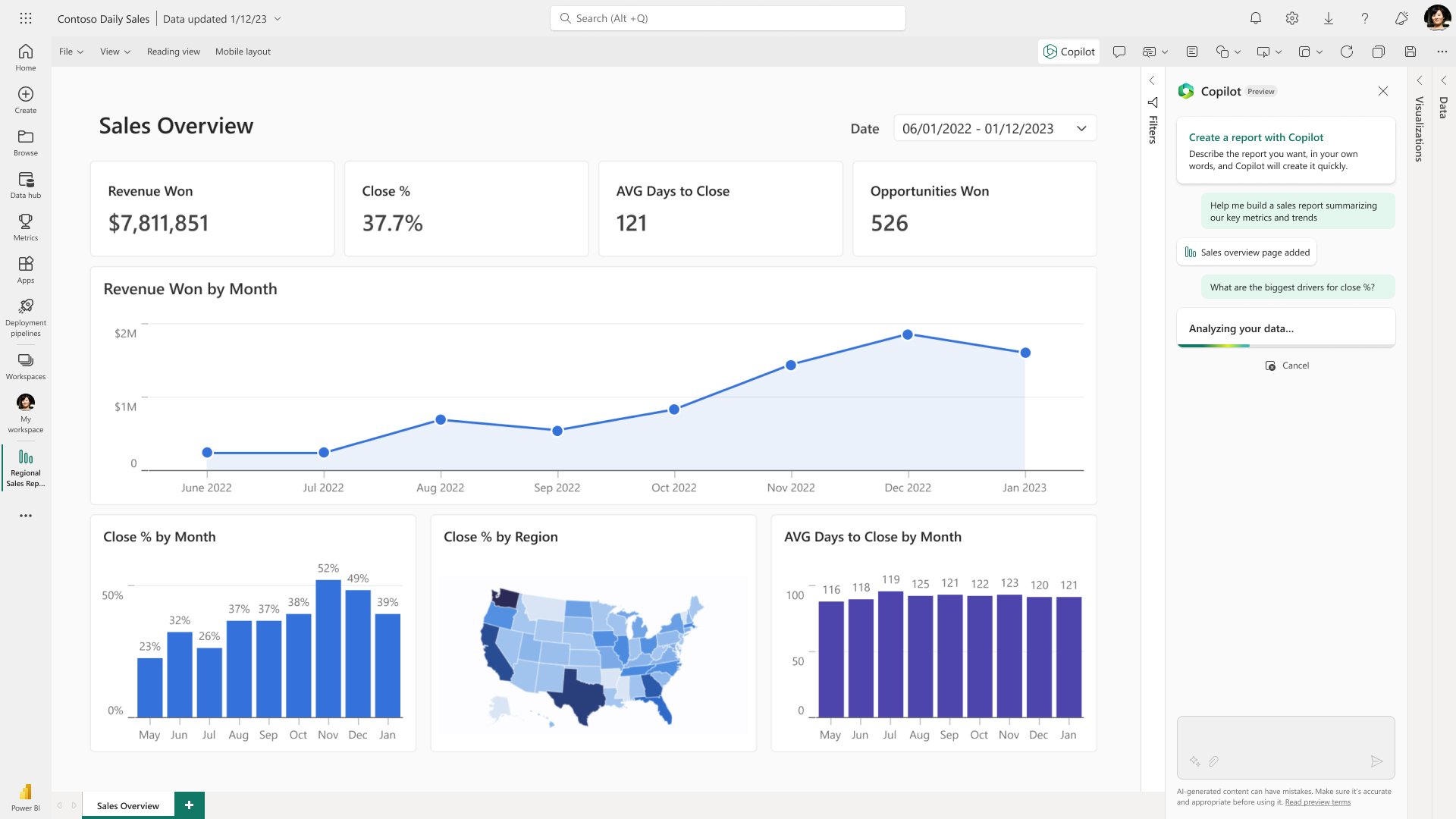
Power BI is at the heart of Fabric and this capability can be seen on top of the other Fabric features. Microsoft have introduced Git integration for Power BI reports and datasets (metadata) and this works within the workspace as well as on desktop. The desktop version has a new file type of .pbip which is a Power BI Project File, and this allows you to commit changes to your reports through Visual Studio Code into a Git tool of your choice.
Another nice feature to call out is ‘Direct Lake mode’ which is a hybrid of ‘Direct Query’ and ‘Import’ modes. Previously, when designing a Power BI report, you would need to decide how your data is brought into the model. You could have the speed of import mode but lose out on having the most recent data or you could sacrifice performance and have the most up to date records. Direct Lake solves this issue by directly scanning the lake to allow highly performant access directly to the data without the typical intermediary Warehouse or Lakehouse layer.
How does everything fit together?
Ok, so we’ve been through what capabilities Fabric has but how do you actually use it? There is a lot to unwrap here so we will stick to just a couple of examples for now. Conceptually, it is the same as Power BI where the artifacts you create all live in a workspace. That’s your main "container”.
One of the paths that you can take to transform your data is to use the Lakehouse artifact which will be the storage mechanism for your data. Here you can use the medallion architecture (Bronze/Silver/Gold) to structure your Lake layers alongside notebooks and Dataflows to transform your data.
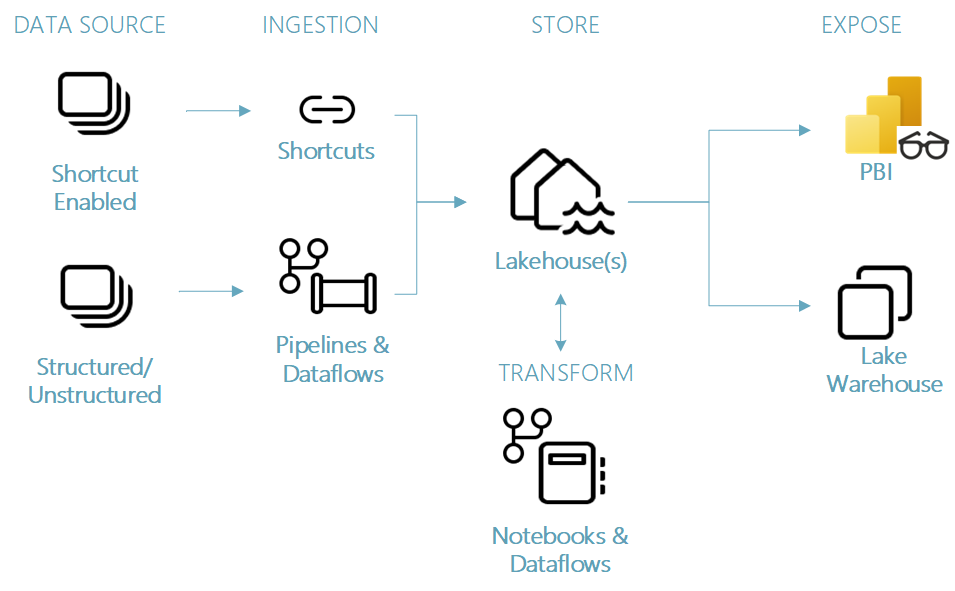
An example ‘happy path’ for using the Lakehouse artifact within Fabric.
Depending on the team skillset and preferences, you can achieve the same result as the Lakehouse path above but by using the Datawarehouse artifact instead. This approach focuses more heavily on a SQL skillset:
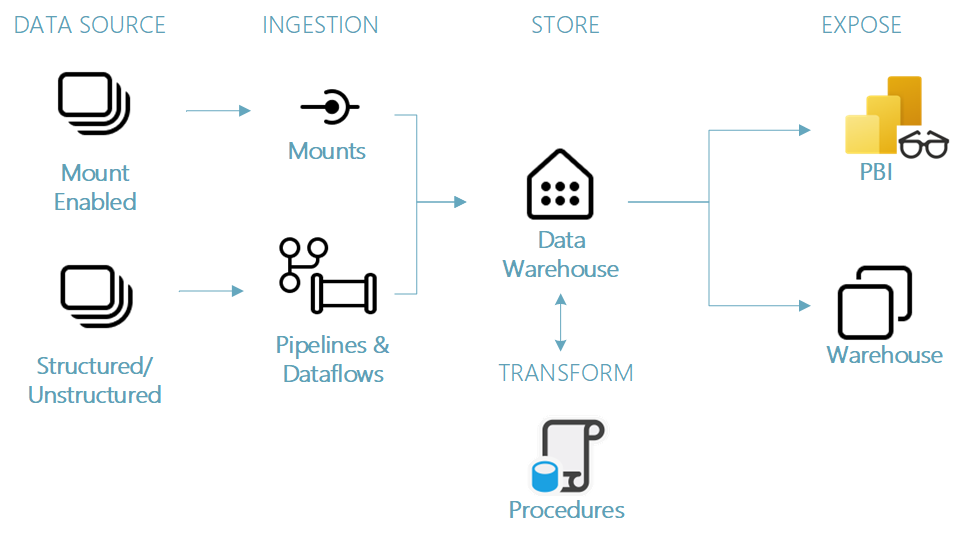
An example of the Datawarehouse ‘happy path’ for end-to-end transformation.
What’s next?
Fabric has some great potential, and we really like a lot of the functionality that we can see under the hood.
Firstly, as a company known for innovating around the Data Lakehouse space, it is great to see that the Lakehouse approach, and Delta as a storage mechanism, is front and center across all workloads in Fabric. That’s a very strong message from Microsoft, and great news for the future of the platform.
We’re also very excited about the integration of Copilot across the different experiences – with this, it’s obvious that Microsoft are pushing for a new type of development experience and a huge step forward in productivity.
DirectLake is another huge feature we’ll explore in more depth – with existing Lakehouse patterns we’ve had to design the mechanisms to serve data from our delta tables in the lake to the in-memory business intelligence models. DirectLake means we can use the Power BI vertipaq engine directly on top of the Delta tables, no importing necessary. That is a huge, powerful message, simplifying architectures and bringing dashboards and the lake closer than ever.
Git integration for Power BI (especially on desktop!) is a hugely positive step and will help a lot of teams, particularly across larger projects, to bring Power BI in line with the rest of their development practices. Microsoft has plans to extend Git integration in Fabric to all artifacts, not just notebooks, reports and datasets which will be a massive gain for pro-code users while bringing low-code users of the platform closer to established development processes without having to learn git commands.
Security is another area that we want to see in more detail to get an understanding of how personas interact with the platform at a deeper level. The platform is open to many personas, and we’d expect a central ability to restrict those experiences to specific users and groups within the tenant.
Overall, Microsoft Fabric brings together a substantial number of analytics capabilities into one place. By removing the overhead of having to deploy and manage infrastructure for all of these services, it simplifies that journey to a modern Data Lakehouse platform which will benefit many organisations. We will be watching this over the coming months to see how some of the capabilities evolve. Be sure to check our blog, YouTube channel, and podcast regularly as we dive into everything Fabric. Alternatively, feel free to contact us to chat about Fabric and how it can revolutionise your data.